8 資料視覺化
8.1 資料視覺化的目的
延續Ch 7,探索式資料分析可分為圖形化Graphical 或 量化Quantitative分析,總括來說作圖的目的有:
- 了解資料的特性
- 尋找資料的模式(patterns)
- 建議資料分析與建模的策略
- 結果呈現與溝通
其中前三項屬於探索圖 (Exploratory graphs),結果呈現與溝通屬於結果圖 (Final graphs),探索圖屬探索式資料分析,目的是在『看』與『觀察』資料的樣子,所以探索圖有以下特性:
- 很快就可以做一張圖
- 探索過程中,可能可以做圖
- 主要目的是了解資料的樣子
- 不用做圖形格式調整美化
而在製作結果圖 (Final graphs)時,則須考慮以下事項:
- 比較,呈現差異
- 比較什麼?誰跟誰比較?
- 呈現因果關係(causality),機制(mechanism),結果解釋(explanation),系統化的結構(systematic structure)
- 因果模型?為什麼你想要做這樣的比較
- 呈現多變數(Multivariate)資料
- 多變數(Multivariate):超過兩個變數就叫多變數
- 所有真實事件都是多變數的
- 將證據整合呈現
- 在同一個畫面呈現文字、數字、影像、圖表
- 盡量用圖形呈現資料
- 將圖表做適當的標記與說明,包括xy軸名稱、單位、資料來源等
- 資料圖表必須可以呈現你想說的故事
- 內容才是最重要的
- 資料不好,分析不好,圖表再美也沒有用
在R中,有三個常用的畫圖套件,包括基本功能(Base)、lattice以及ggplot2,由於各套件繪圖邏輯不同,本書只介紹最推薦的ggplot2套件的使用方式。
8.2 ggplot2簡介
ggplot2 (Wickham, Chang, et al. 2020)的開發靈感來自於Dr. Leland Wilkinson的Grammar of Graphics
“In brief, the grammar tells us that a statistical graphic is a mapping from data to aesthetic attributes (colour, shape, size) of geometric objects (points, lines, bars). The plot may also contain statistical transformations of the data and is drawn on a specific coordinate system”
-from ggplot2 book
ggplot2 Package是由Hadley Wickham開發,是第三個R的畫圖Package。自發表以來一直是最熱門的R packages之一,目前還在持續發展更新中,對原始碼有興趣的人可以到GitHub看一下最新動態。
簡單來說,做圖的文法包括兩個最主要元素:
- Aesthetic attributes:包括顏色、形狀、點的大小與線的粗細等
- Geometric objects:包括點、線、盒狀圖、直條圖等
其他元素包括:
- Facets:提供在同一張圖內做多個子圖的方法,只要使用Faceting功能設定子圖分類的依據參數即可
- Stats:將資料做統計轉換
- Scales:修改點線的顏色、形狀、xy軸的範圍等
在開始學ggplot2的核心功能之前,qplot()是ggplot2 Package提供最基本的畫圖方法,跟基本的plot() function很接近,提供一個簡單入門的方法。
8.2.1 qplot()
qplot()為ggplot2 “Hello, world!”,簡單使用qplot(x軸名稱,y軸名稱,data=使用資料)就可畫散佈圖
library(SportsAnalytics)
NBA1516<-fetch_NBAPlayerStatistics("15-16") ## 讀入資料
library(ggplot2) #記得將ggplot2 package讀入,如果沒安奘記得先安裝
qplot(FieldGoalsAttempted, TotalPoints, data = NBA1516)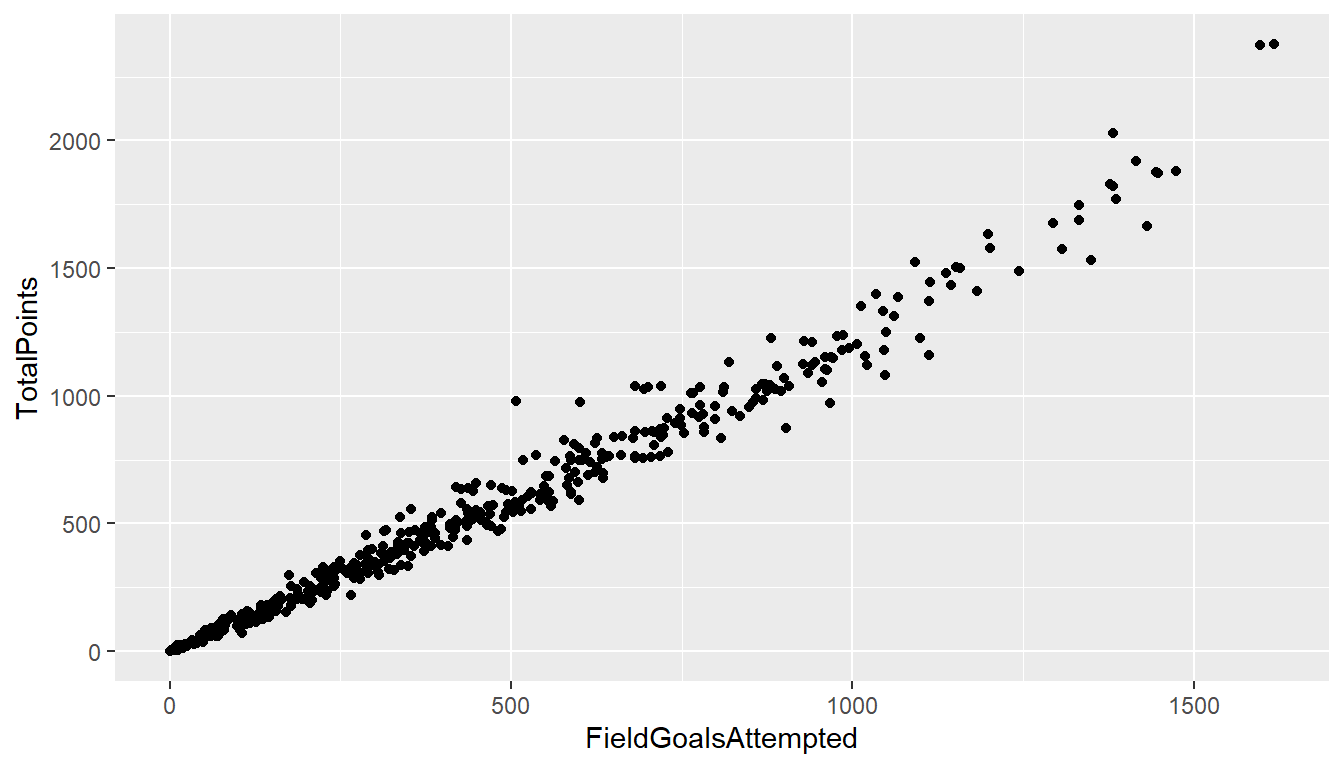
針對做圖的文法的第一個主要元素Aesthetics(包括顏色、形狀、點的大小與線的粗細等),可透過增加指令做修改,如加上color=Position,表示用守備位置Position著色
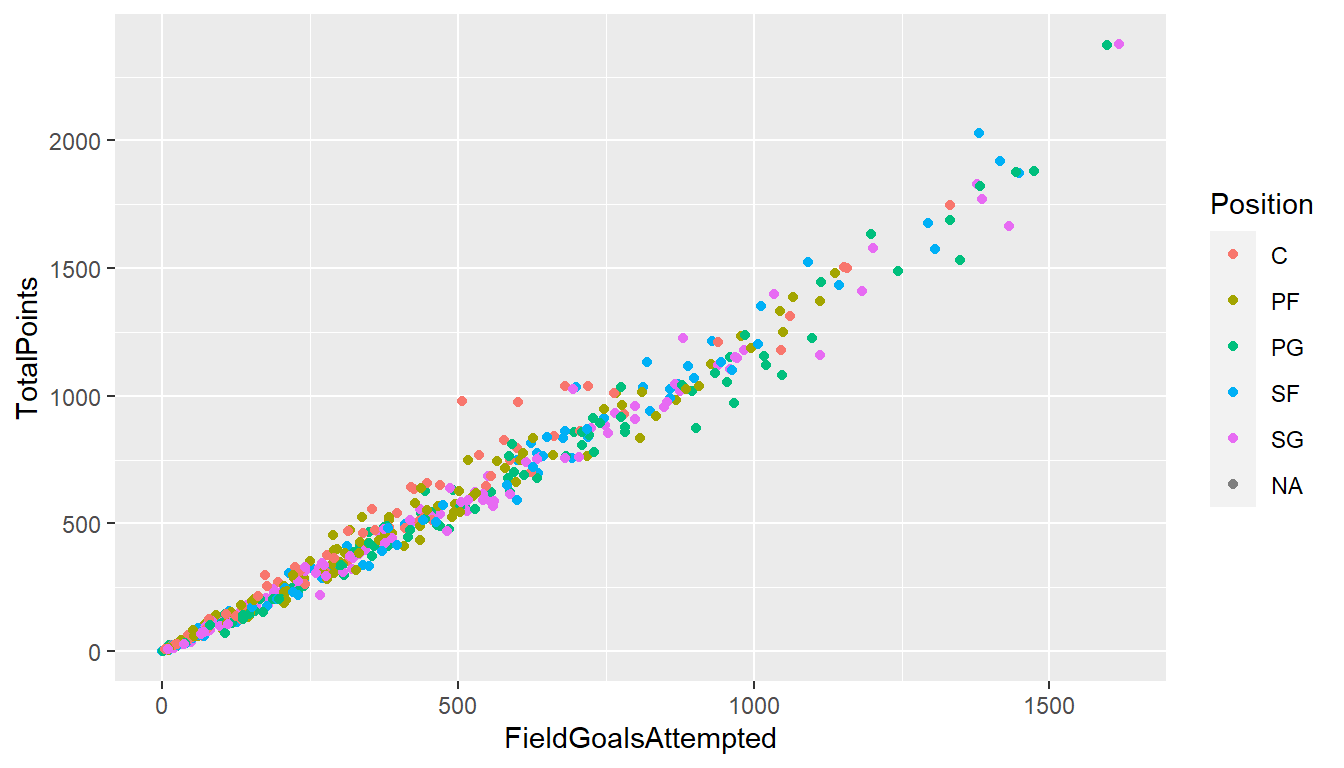 針對做圖的文法的第二個主要元素Geometric(包括點、線、盒狀圖、直條圖等),也可透過增加指令修改,如使用
針對做圖的文法的第二個主要元素Geometric(包括點、線、盒狀圖、直條圖等),也可透過增加指令修改,如使用geom = c("point", "smooth") 在圖上加點與漸進線
## `geom_smooth()` using method = 'loess' and formula 'y ~ x'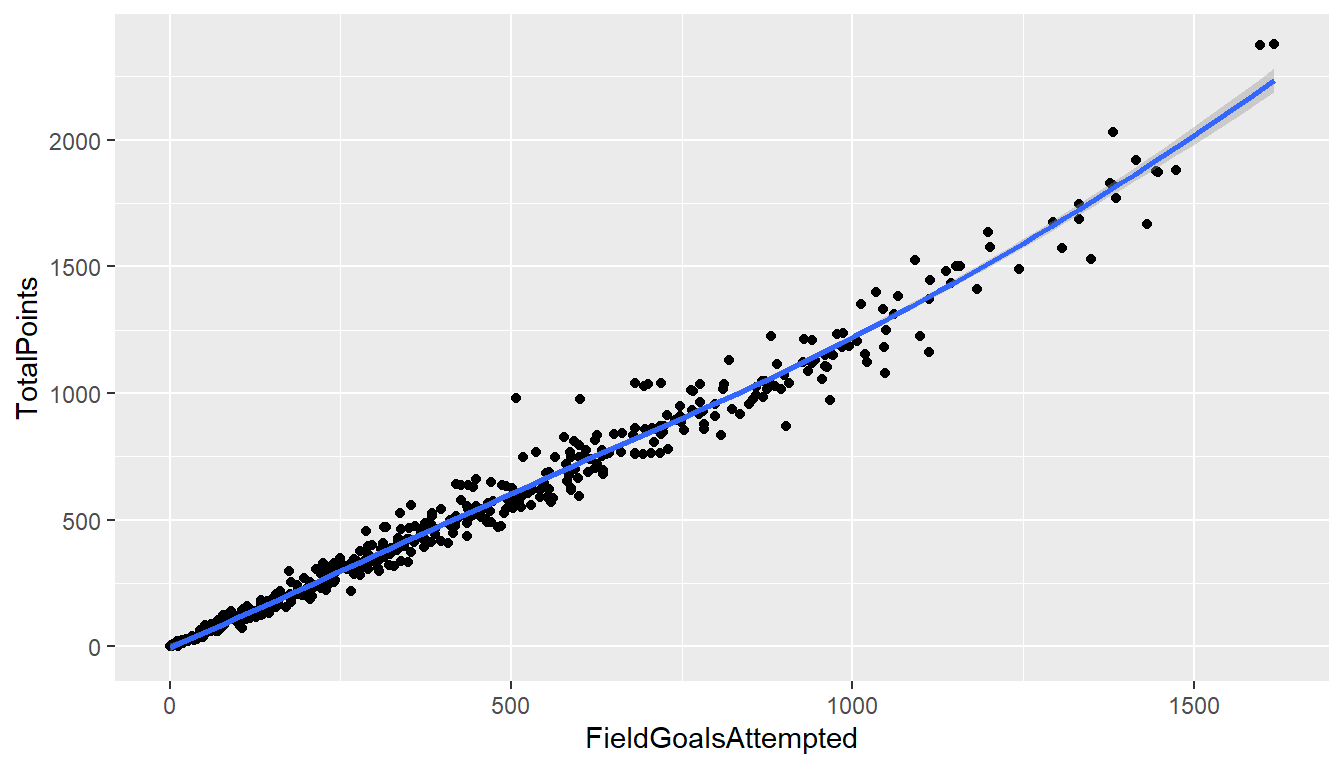
如果輸入的變量並非雙變量,而是單變量時,預設圖形會從散佈圖變為Histograms直方圖
#畫TotalPoints的直方圖/ fill = Position 並用守備位置Position著色
qplot(TotalPoints, data = NBA1516, fill = Position)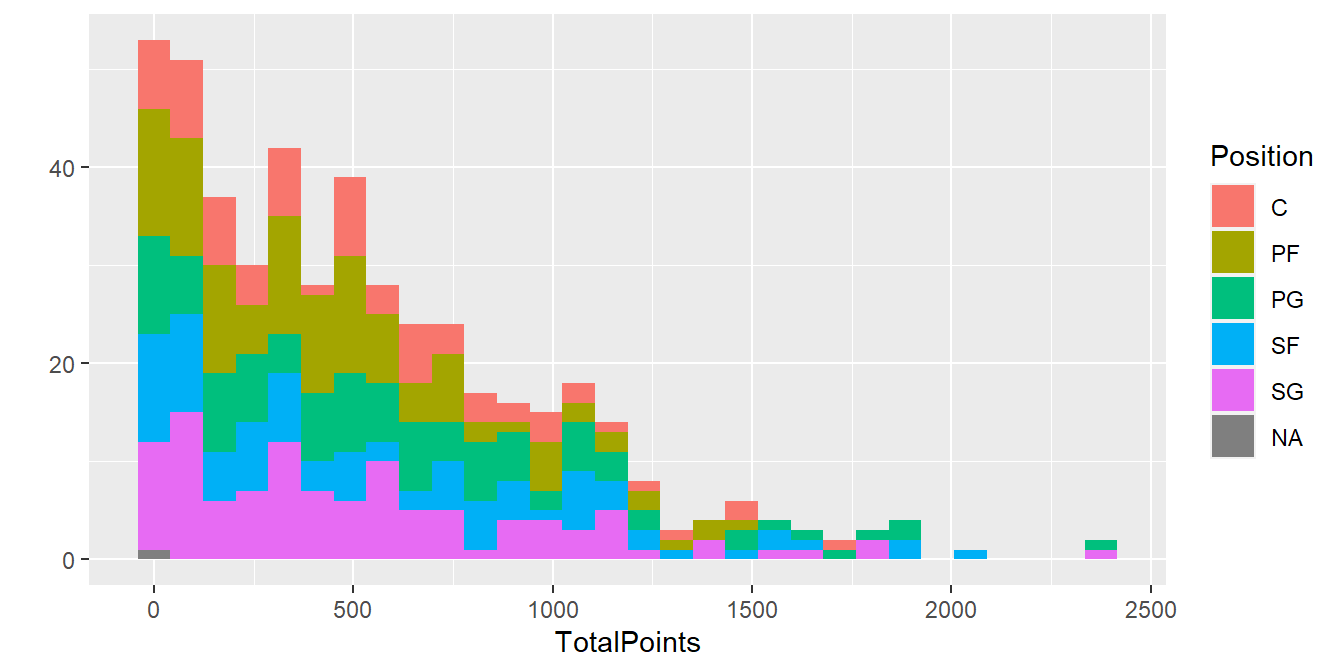
作圖的Facets元素可提供在同一張圖內做多個子圖的方法,只要使用facets =來設定子圖分類的依據參數即可,以下圖為例,輸入的變量是雙變量,所以預設圖形為散佈圖,而設定子圖的語法為直向分類~橫向分類,直向分類意指以增加列(Row)的方式畫子圖,橫向分類意指以增加行(Column)的方式畫子圖,通常只會設定單一方向,如果選擇的是直向,橫向分類部分可用.表示,範例如下:
#facets = . ~ Position 用守備位置Position分群畫圖(橫向)
qplot(FieldGoalsAttempted, TotalPoints,
data = NBA1516,
facets = . ~ Position)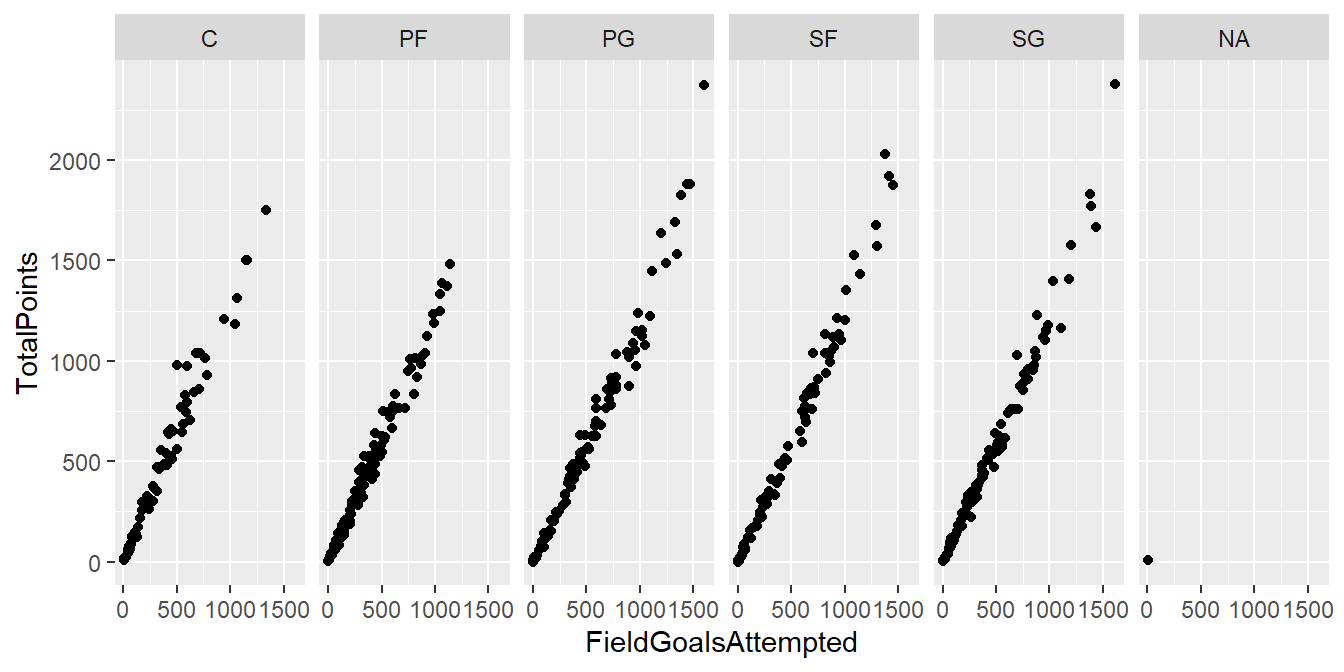
#facets = . ~ Position 用守備位置Position分群畫圖(直向)
qplot(FieldGoalsAttempted, TotalPoints,
data = NBA1516,
facets = Position ~ .)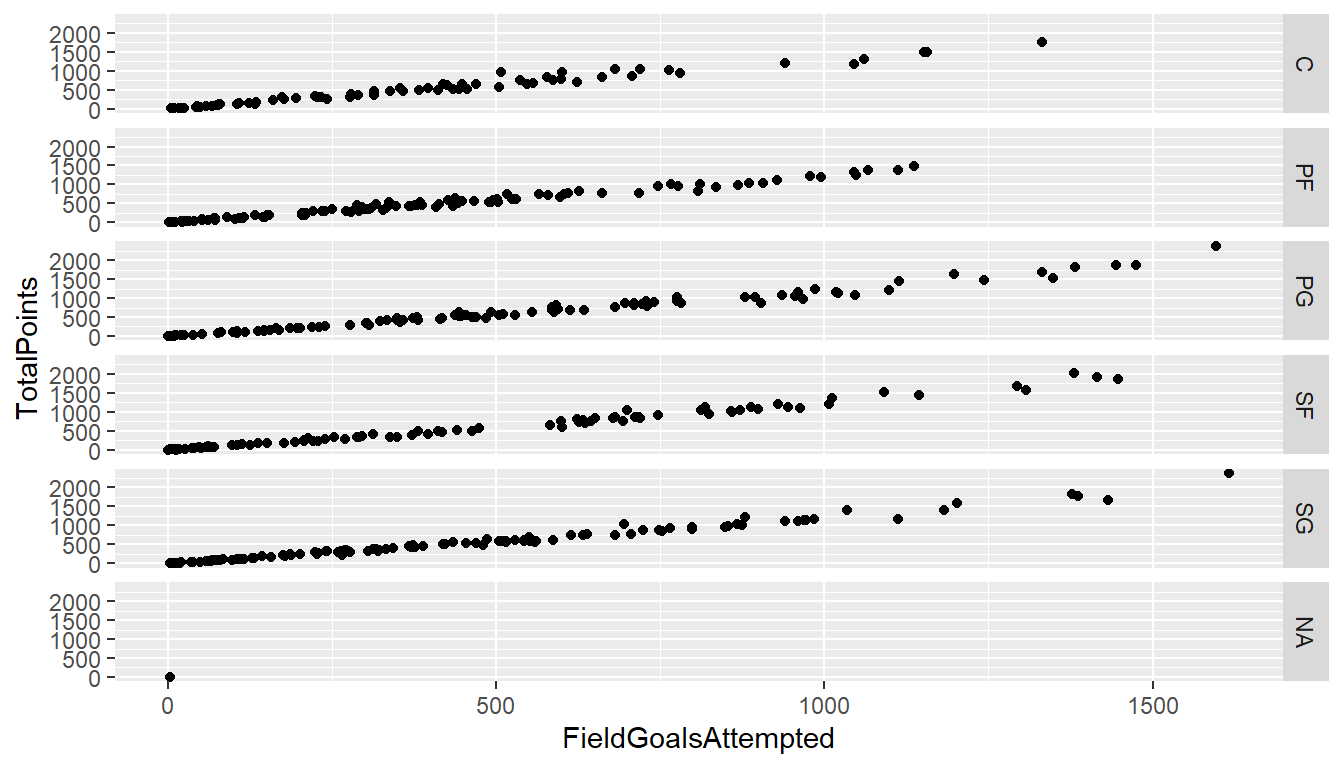
ggplot2套件會自動幫使用者選擇顏色與圖形各項參數,但使用者也可依需求微調,如直方圖的分組間隔,可透過binwidth參數設定
#facets = . ~ Position 用守備位置Position分群畫圖(直向)
##binwidth = 2 每2分一組
qplot(TotalPoints, data = NBA1516,
facets = Position ~ ., binwidth = 2)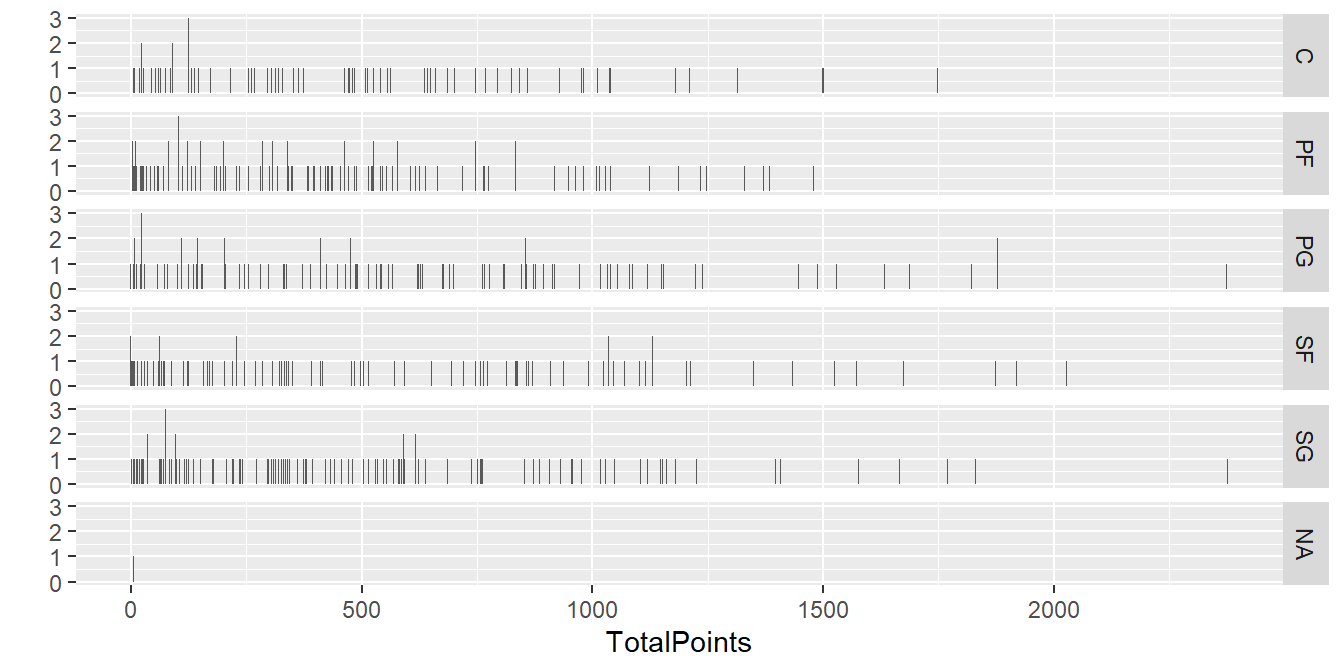
#facets = . ~ Position 用守備位置Position分群畫圖(直向)
##binwidth = 100 每100分一組
qplot(TotalPoints, data = NBA1516,
facets = Position ~ ., binwidth = 100)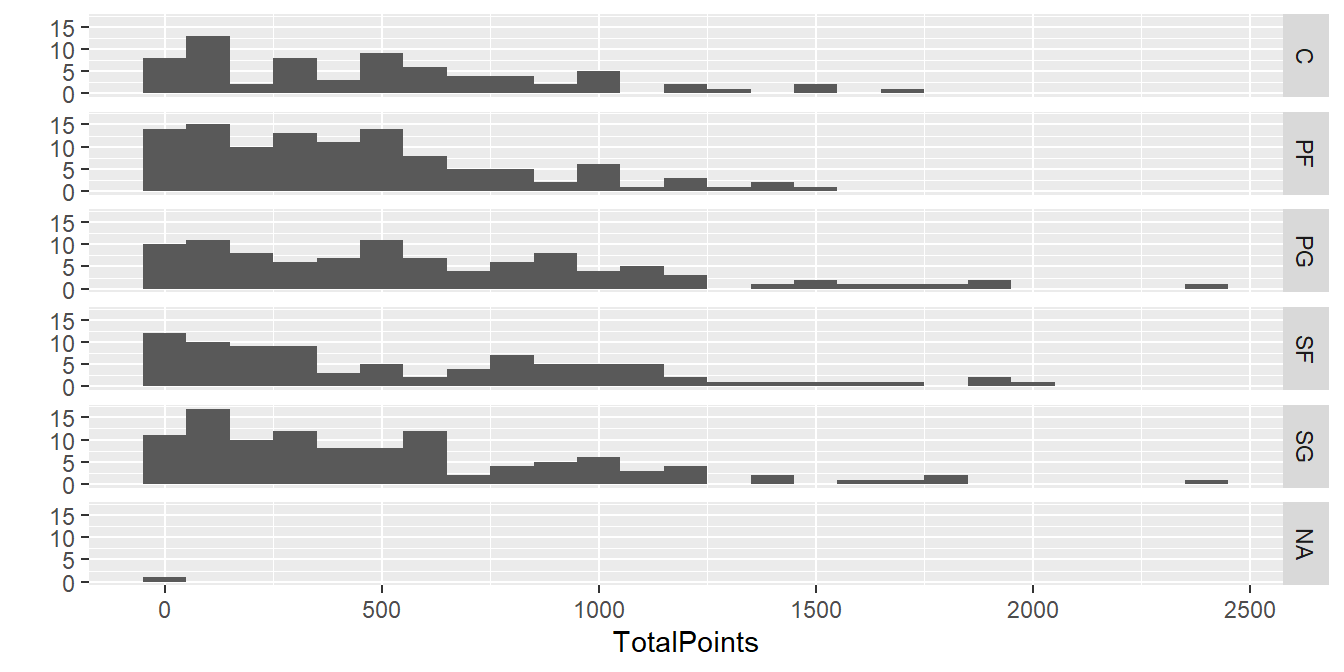
總括來說qplot()提供快速方便的畫圖功能,並且保留部分參數設定的彈性,但若需要調整更多參數,仍須使用完整的ggplot()函式。
8.2.2 ggplot()
使用ggplot2作圖有以下步驟:
- 準備好資料。當然要有資料才能畫圖
- 設定Aesthetic attributes。使用
aes(x, y, ...)指定 - 指定Geometric objects。常用的包括
geom_point()、geom_line()、geom_histogram()、geom_polygon()、geom_errorbar()
首先先產生教學用畫圖資料
設定兩個畫圖的重要元素Aesthetic attributes和Geometric objects
 用
用geom_boxpolt()改畫盒狀圖
 使用Faceting功能
使用Faceting功能
 轉向
轉向
 用
用geom_smooth()替xy散佈圖加上趨勢線
## `geom_smooth()` using method = 'loess' and formula 'y ~ x'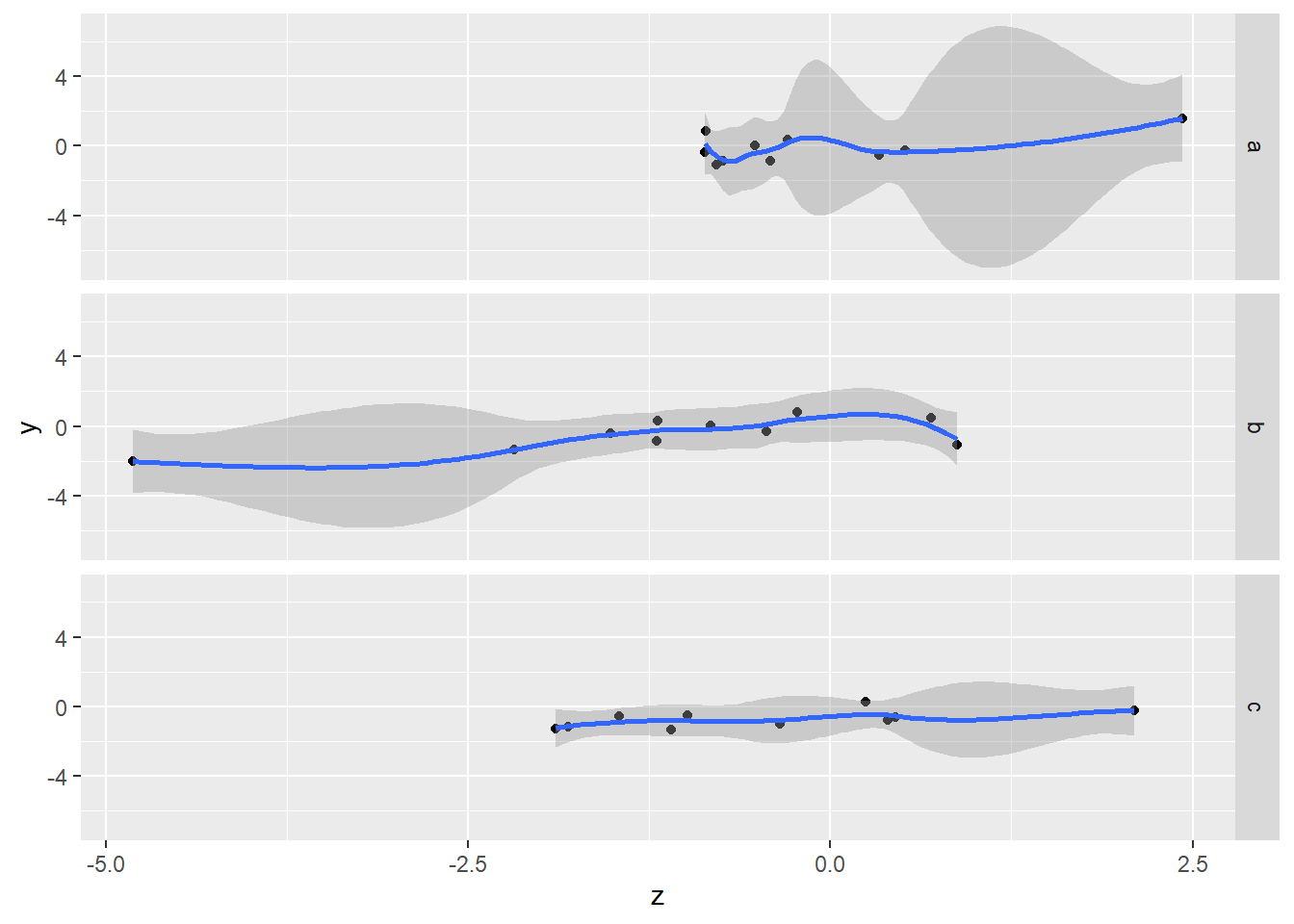 用
用geom_smooth()替xy散佈圖加上趨勢線,使用linear regresion
## `geom_smooth()` using formula 'y ~ x'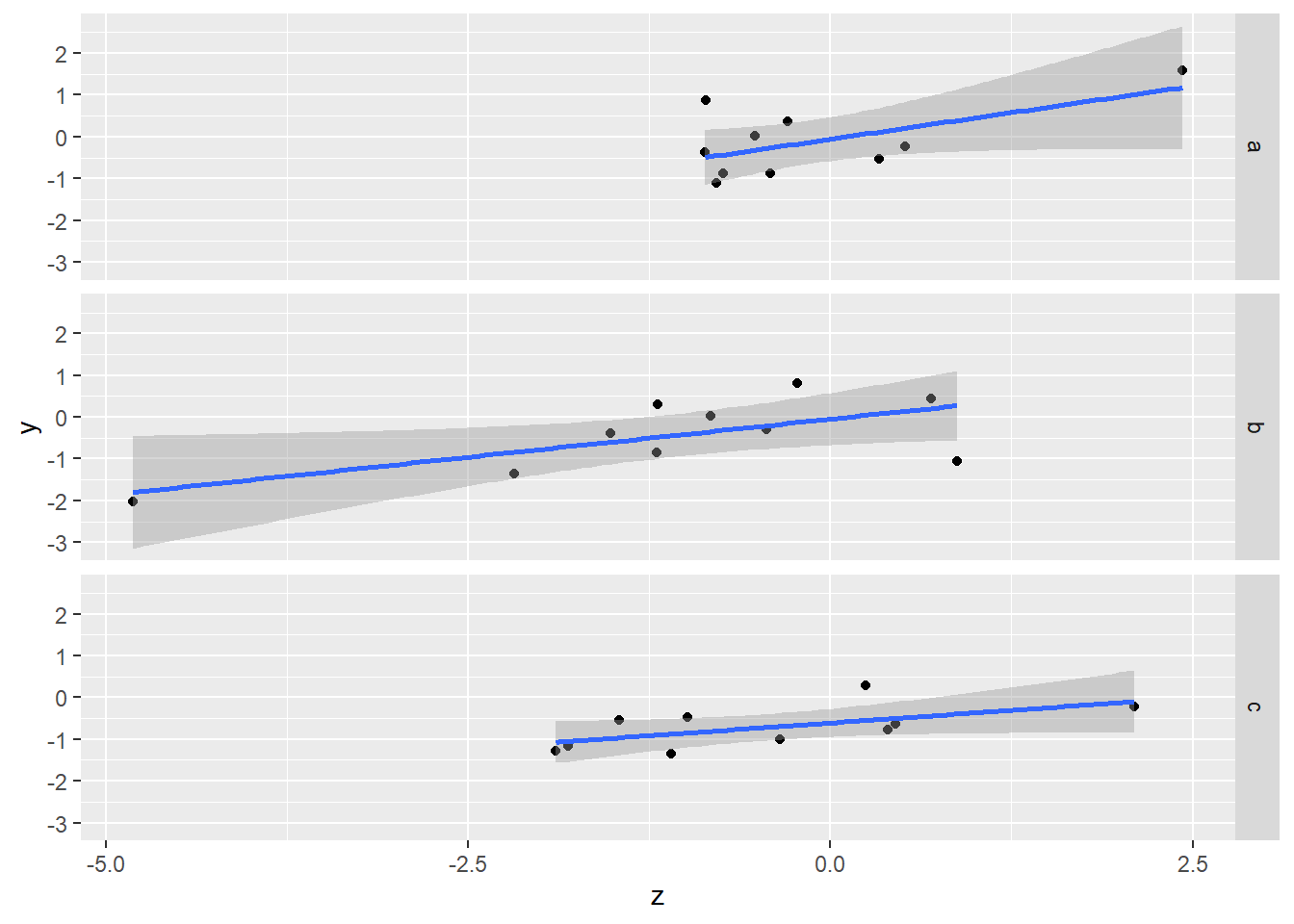 改用
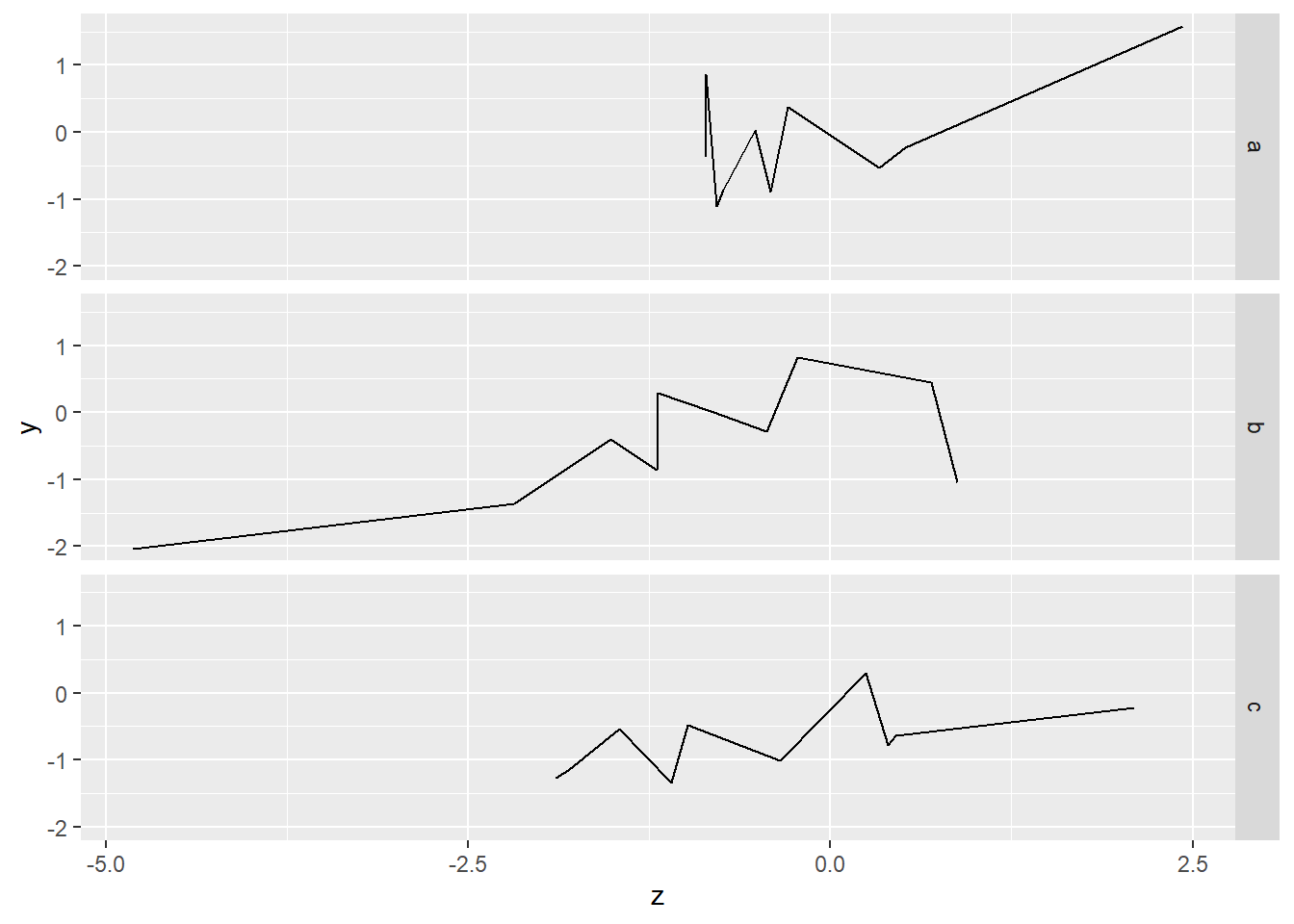
改用geom_line()畫線
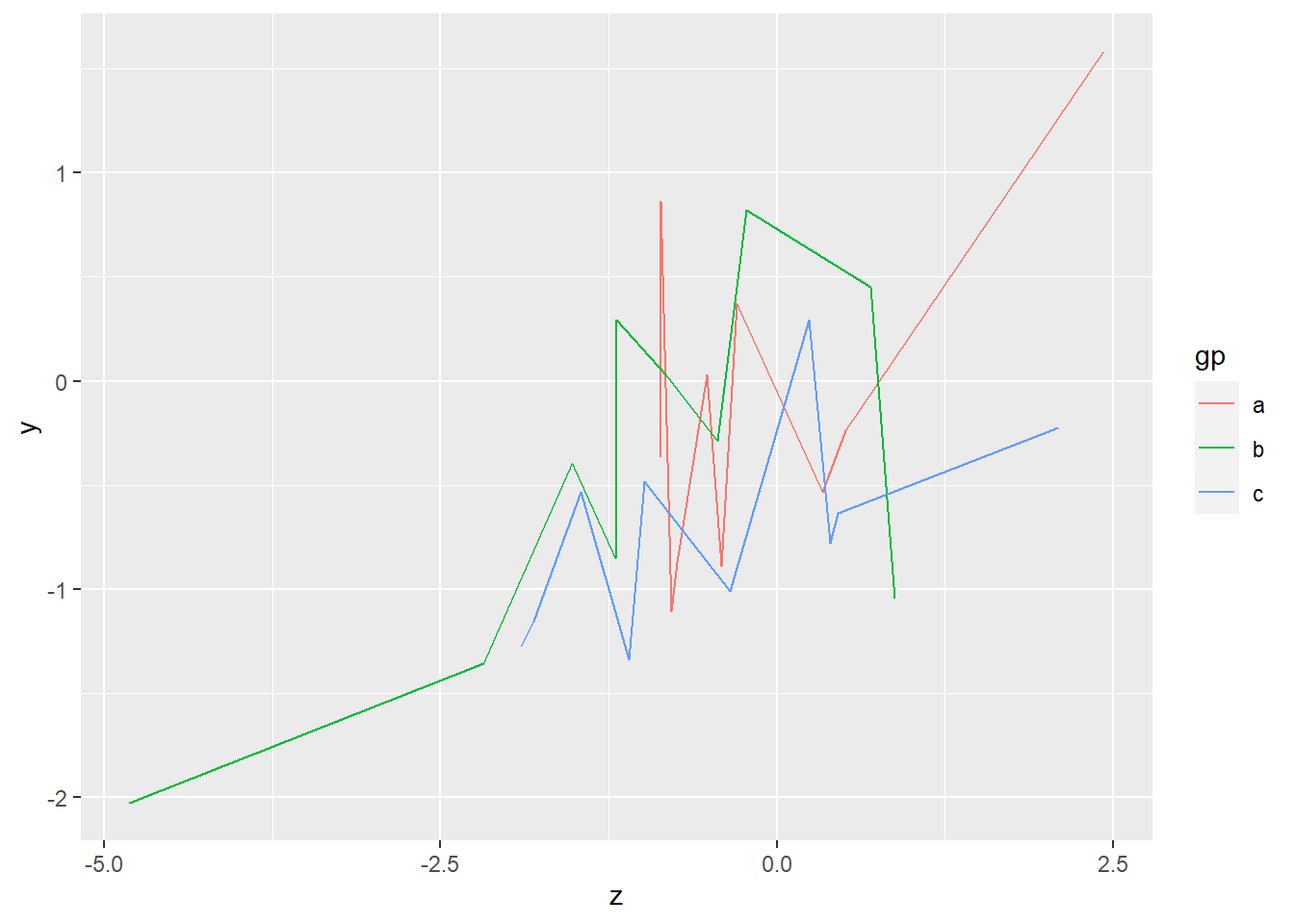
 改用顏色分組,使用
改用顏色分組,使用aes(color='group name')
畫圖前需要注意的幾個小地方:
提供資料時,把資料修改為想要在圖片顯示的文字。從上面的範例可以發現,ggplot2會直接將資料分組(a/b/c)直接標在圖上,與其之後再來改圖,不如在資料處理時就將a/b/c改為有意義且可以直接使用的文字。 如果是離散性的資料,但卻又是數值時(像是1,2,3)可以用factor()轉換,ggplot會將factor視為離散資料。
除了基本的製圖外,ggplot2套件也提供完整的資料標示設定與其他參數設定功能,包括:
- 標籤
xlab(),ylab(),labs(x=,y=),ggtitle() - 每一個
geom_*()都有參數可設定 - 圖形樣式設定
theme(),可使用內建樣式theme_gray(): 灰背景,預設樣式theme_bw(): 黑白樣式
- 使用其他樣式套件
在比較多組的平均值高低時,因為各組樣本數與資料分佈不同,平均數的誤差值也會不同,所以在資料視覺化時,建議加上誤差線(Error bar),誤差線通常使用在bar chart和line chart,而誤差值的計算有下列三種選擇:
- Standard deviation (SD) 標準差:呈現資料本質時使用
- Standard error (SE) 標準誤差:呈現預估平均值的可能誤差時使用
- Confidence interval (CI) 信賴區間:呈現預估平均值的信心時使用
以空氣污染料為例,若想比較各月臭氧濃度差異,可以使用bar chart來呈現,在ggplot2中,如果要畫bar chart,需要將Geometric objects設定為geom_bar
library(datasets)
library(data.table)
airquality$Month<-as.factor(airquality$Month) #將Month轉為因子變項
airquality.mean<-data.table(airquality)[,.(OzoneMean=mean(Ozone,na.rm = T)),by=Month] #計算每月Ozone平均
ggplot()+geom_bar(data=airquality.mean,aes(x=Month,y=OzoneMean),
stat = "identity") #stat = "identity" 直接畫數字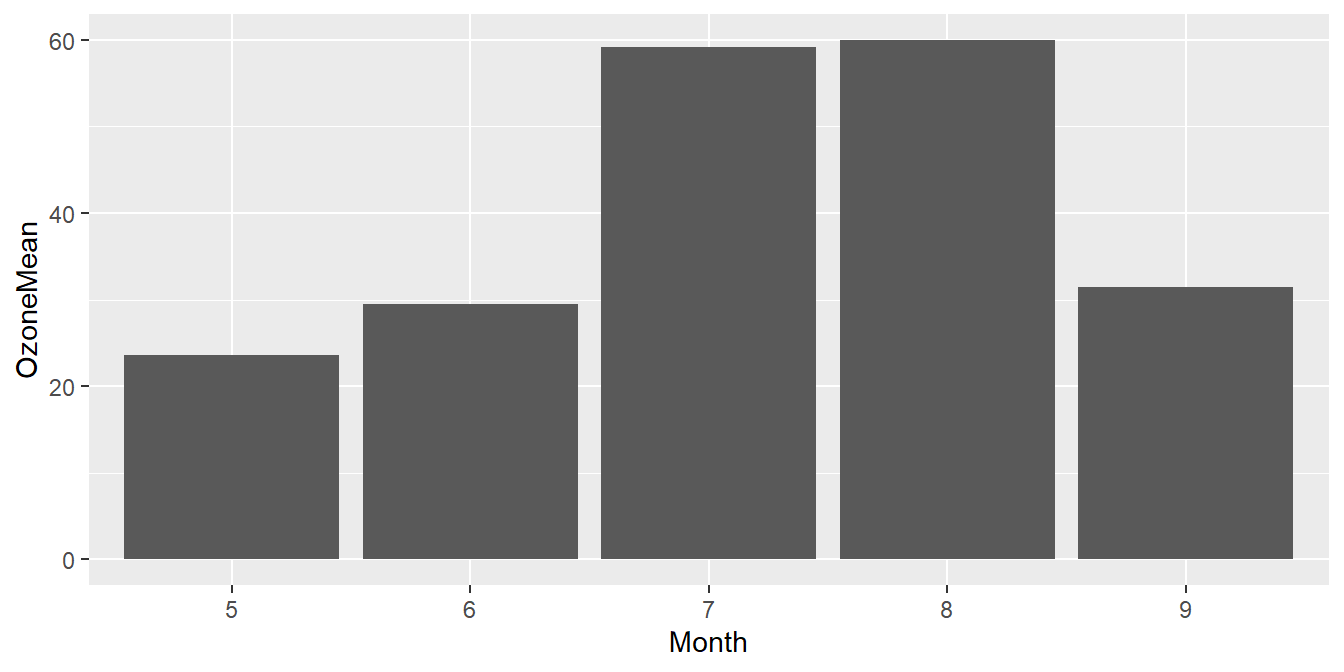
在ggplot2套件中,只要加上geom_errorbar()函式,設定資料高低值,就能在原圖中加上誤差線
library(datasets)
library(data.table)
airquality$Month<-as.factor(airquality$Month) #將Month轉為因子變項
airquality.stat<-data.table(airquality)[,.(OzoneMean=mean(Ozone,na.rm = T),OzoneSD=sd(Ozone,na.rm = T)),by=Month] #計算每月Ozone平均與標準差
ggplot(data=airquality.stat)+ #資料airquality.eb
geom_bar(aes(x=Month,y=OzoneMean),stat = "identity")+
geom_errorbar( #ymin低點, ymax高點
aes(x=Month,ymin=OzoneMean-OzoneSD,ymax=OzoneMean+OzoneSD), width=.1)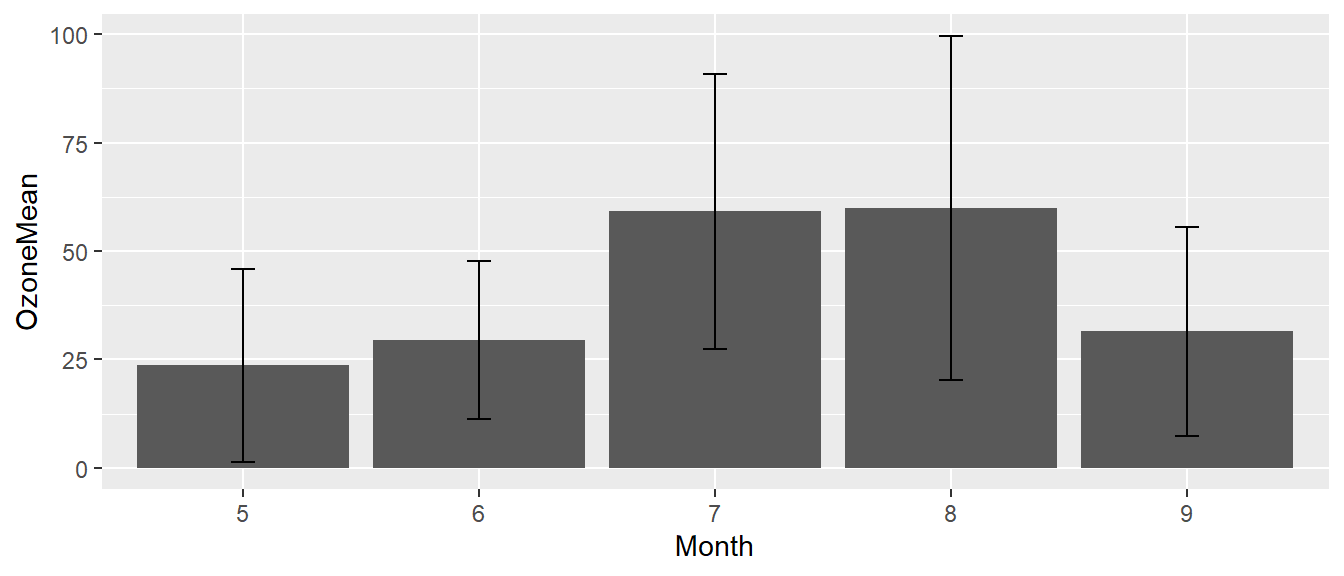
8.3 ggplot2+地圖
8.3.1 Choropleth map面量圖
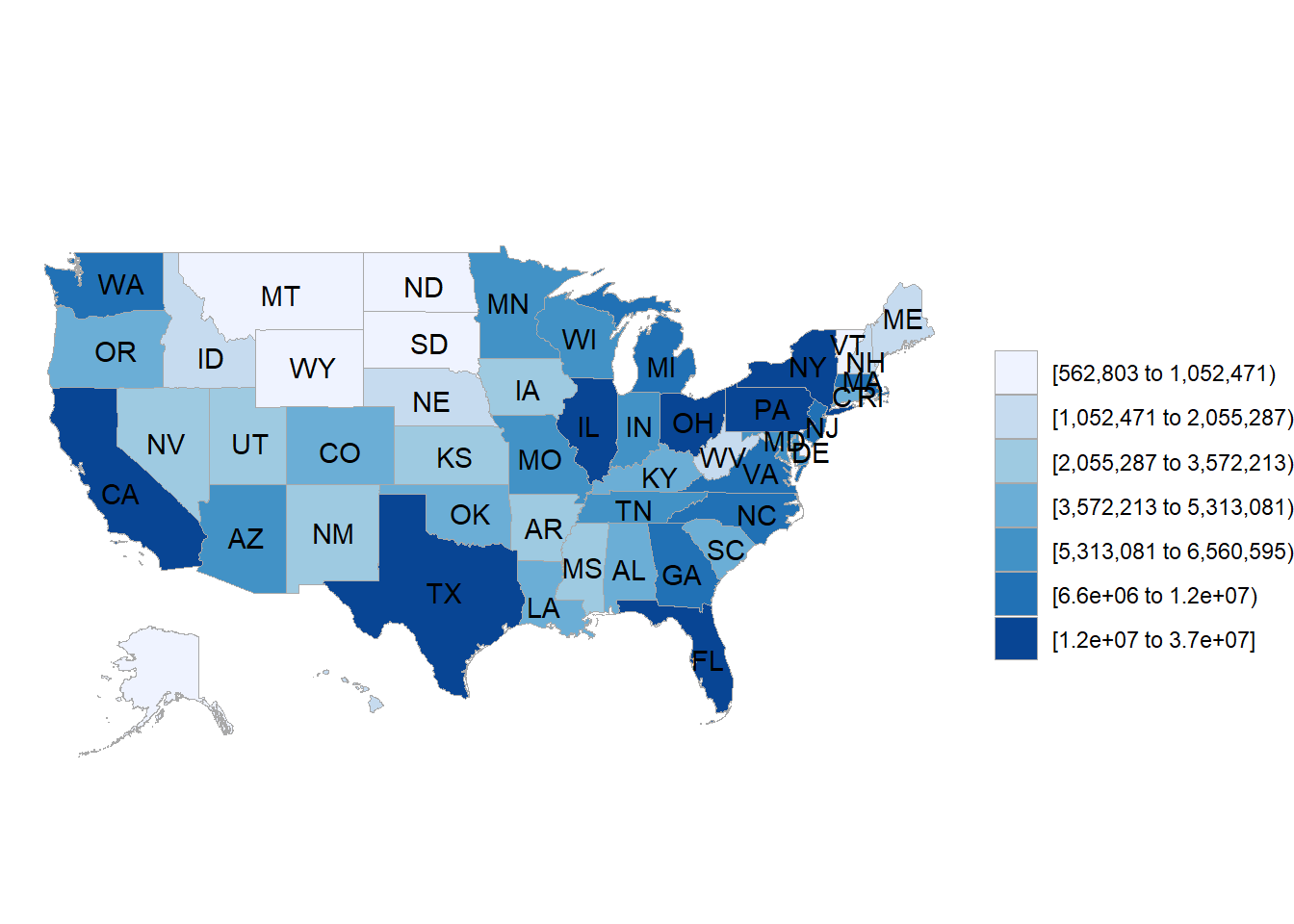
Choropleth map面量圖是指把統計資料用顏色畫在對應的地圖上的一種資料視覺化方式,在R中可以使用choroplethr(Lamstein 2018) package來畫面量圖,
choroplethr package是一個基於ggplot2 package的面量圖做圖工具,使用前需要先安裝,建議同時安裝choroplethrMaps package
choroplethr(Lamstein 2018) package內建美國各州地圖與人口學資料,所以可以輕鬆使用state_choropleth()函式畫出美國各州人口分布
若將reference_map設定為= TRUE,可在面量圖的背景加上google地圖,因google地圖需要使用API key,因此須先使用ggmap套件的register_google(key = "your key"),帶入google金鑰設定授權金鑰。以下金鑰為示範金鑰,目前已失效,請自行至Google Cloud Platform,點選API及服務申請Maps Static API後,複製API key。
[2020/05/25更新]:似乎需在Google Cloud Platform 綁定服務使用付款信用卡才可以順利經由ggmap套件取得圖層。
data(continental_us_states)
library(ggmap)
register_google(key = "AIzaSyBD_nXDjGMYcJO9e_3SI_h3YZwhx0if680") #demo key
state_choropleth(df_pop_state,reference_map = TRUE,
zoom= continental_us_states) #把各州人口畫在地圖上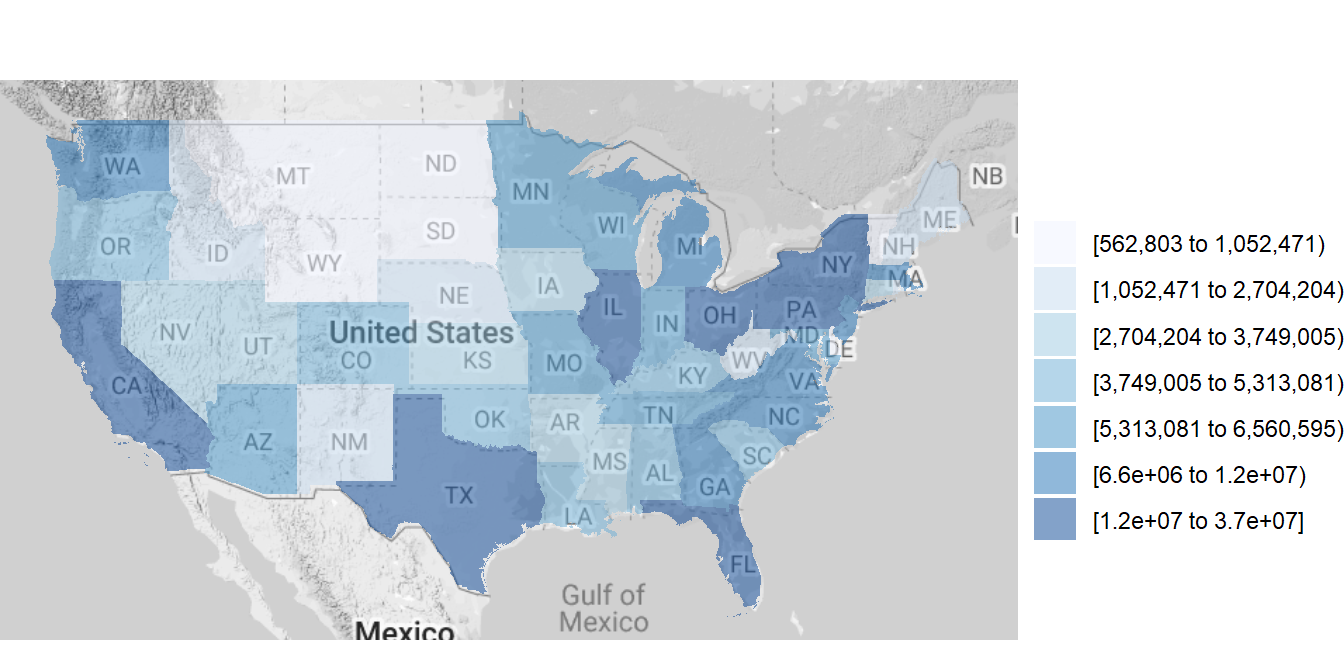
除了美國地圖外,使用choroplethr package搭配WDI: World Development Indicators 的世界人口分布資料,可以針對世界人口分佈做面量圖。
世界人口資料的代碼為SP.POP.TOTL,代碼查詢可見World Development Indicators
由於需要使用WDI的資料,所以需要安裝與載入WDI(Arel-Bundock 2020) package
除了人口資料外,WDI也有世界平均壽命資料,平均壽命的代碼為SP.DYN.LE00.IN,代碼查詢可見World Development Indicators
如果只需亞洲太平洋人口分布,可使用zoom參數設定想畫的國家,國家的名稱設定必須要和country.regions資料完全吻合
8.3.2 ggmap()
ggmap(Kahle, Wickham, and Jackson 2020) package是一個可以把google map載入並作圖的套件,一樣是基於ggplot2套件開發的。
依照往例,第一次使用前需要安裝
載入ggmap(Kahle, Wickham, and Jackson 2020) package後,可以使用get_googlemap()函式取得google map圖層,並用ggmap()函式將取得的圖層畫出來,使用google map的資源時,必須先使用register_google(key = “your key”)帶入google金鑰。
投影片金鑰已失效,請自行至Google Cloud Platform,點選API及服務申請Maps Static API後,複製API key。
[2020/05/25更新]:似乎需在Google Cloud Platform 綁定服務使用付款信用卡才可以順利經由ggmap套件取得圖層。
get_googlemap()函式需要設定的參數如下:
- center 中心點經緯度座標
- zoom 放大倍率
- language 地圖語言
library(ggmap)
register_google(key = "AIzaSyBD_nXDjGMYcJO9e_3SI_h3YZwhx0if680")#demo key
twmap <- get_googlemap(center = c(lon=120.58,lat=23.58),
zoom = 7,
language = "zh-TW")
ggmap(twmap)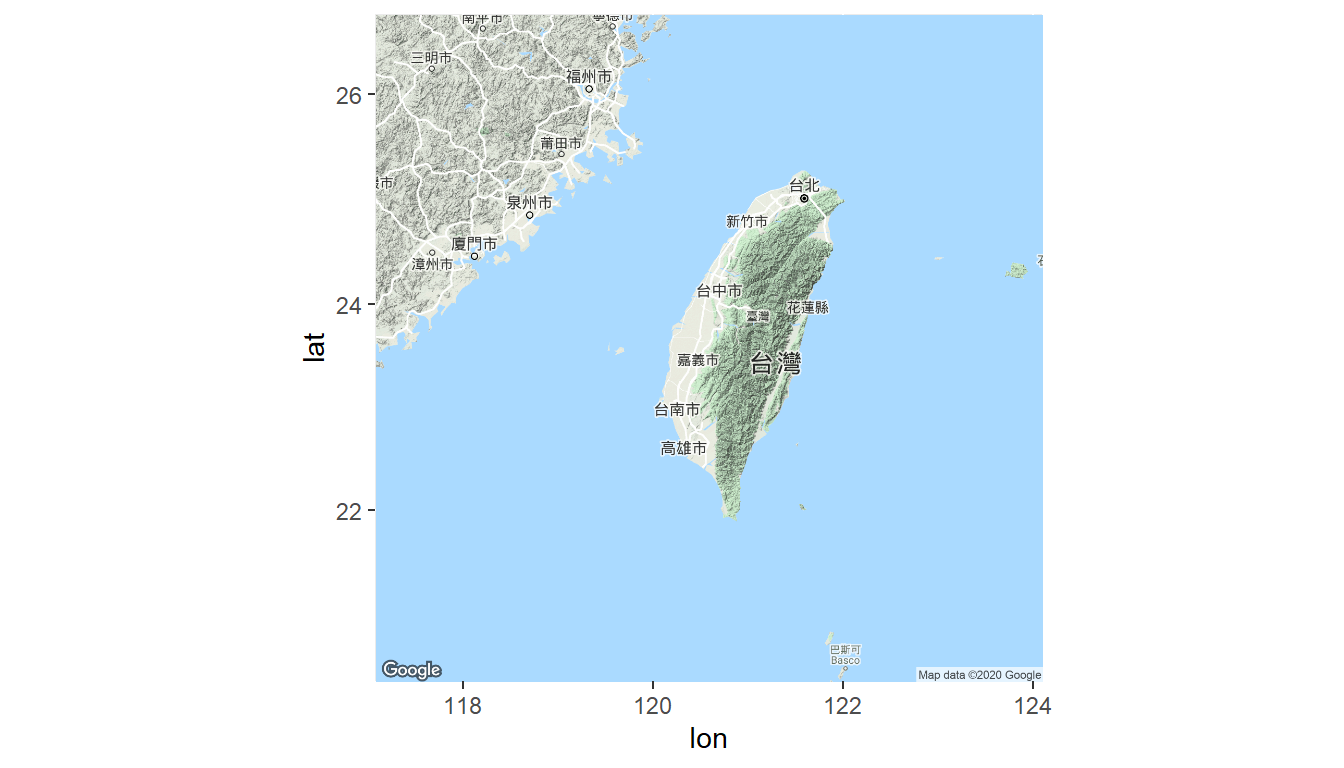
只要資料有經緯度等資訊,就可以使用ggmap package與各式資料結合呈現,以台北市水質地圖開放資料為例,首先先將資料載入處理(參考Ch ??)。台北市水質資料的Open data API網址是http://data.taipei/opendata/datalist/apiAccess?scope=resourceAquire&rid=190796c8-7c56-42e0-8068-39242b8ec927
##資料載入
library(jsonlite)
library(RCurl)
WaterData<-fromJSON(getURL("http://data.taipei/opendata/datalist/apiAccess?scope=resourceAquire&rid=190796c8-7c56-42e0-8068-39242b8ec927"))
WaterDataFrame<-WaterData$result$results
WaterDataFrame$longitude<-as.numeric(WaterDataFrame$longitude)
WaterDataFrame$latitude<-as.numeric(WaterDataFrame$latitude)
WaterDataFrame$qua_cntu<-as.numeric(WaterDataFrame$qua_cntu)
##結合ggmap
library(ggmap)
TaipeiMap <- get_googlemap(
center = c(lon=121.50,lat=25.06),
zoom = 11, maptype = 'roadmap')
TaipeiMapO <- ggmap(TaipeiMap)+
geom_point(data=WaterDataClean,
aes(x=longitude, y=latitude,
color=qua_cntu),size=3.5)+
scale_color_continuous(
low = "yellow",high = "red")+
guides(size=FALSE)
TaipeiMapO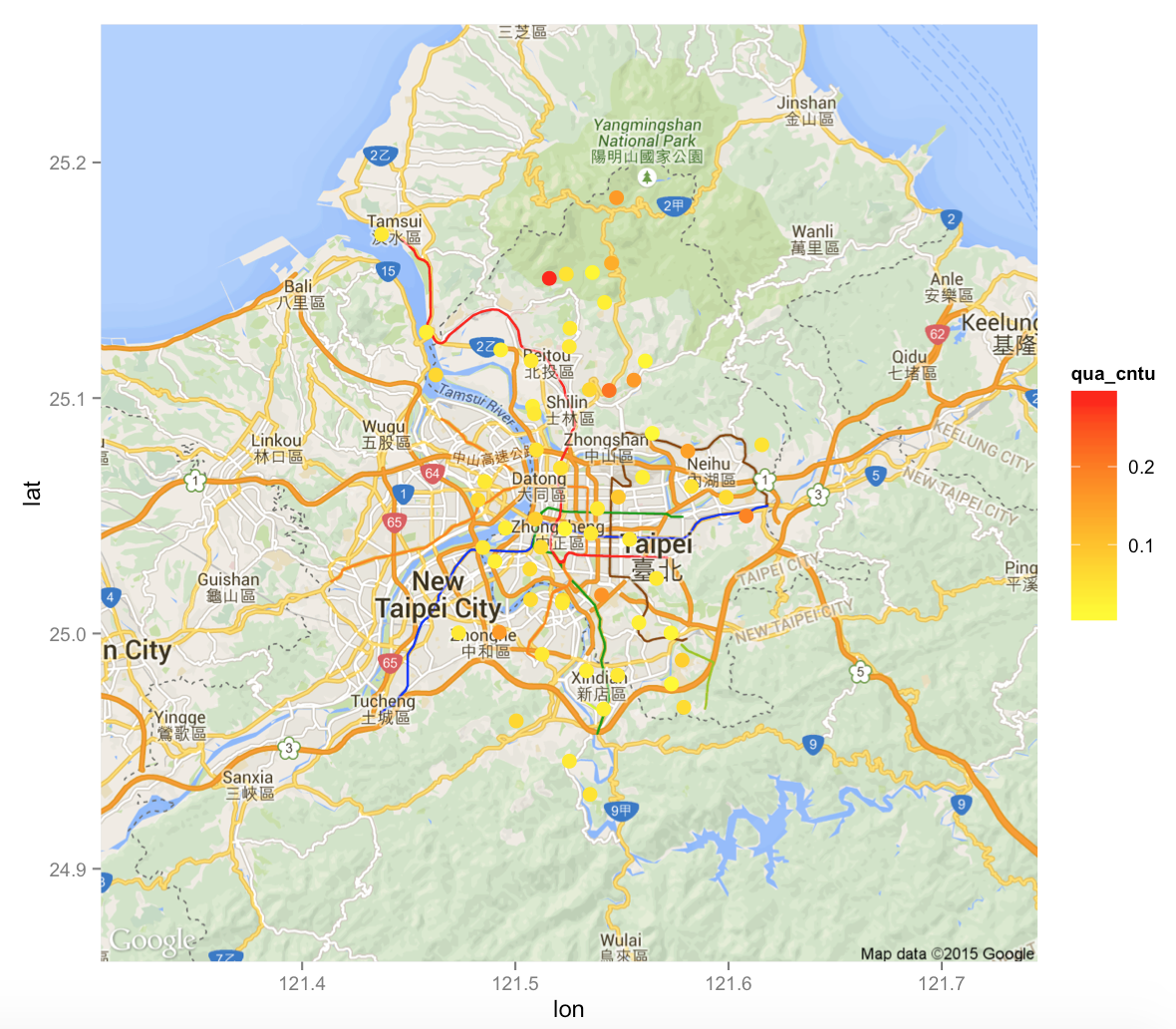
ggmap套件提供多種地圖型態,使用者可透過設定maptype自行選擇適合的地圖樣式,樣式有:
- terrain
- terrain-background
- satellite
- roadmap
- hybrid (google maps)
- watercolor
- toner (stamen maps)
透過設定extent參數可將地圖輸出樣式改為滿版
###Density Map
除了面量圖外,密度圖Density Map也是常用來表示因地理位置不同的數值差異,以下是美國人口密度圖範例
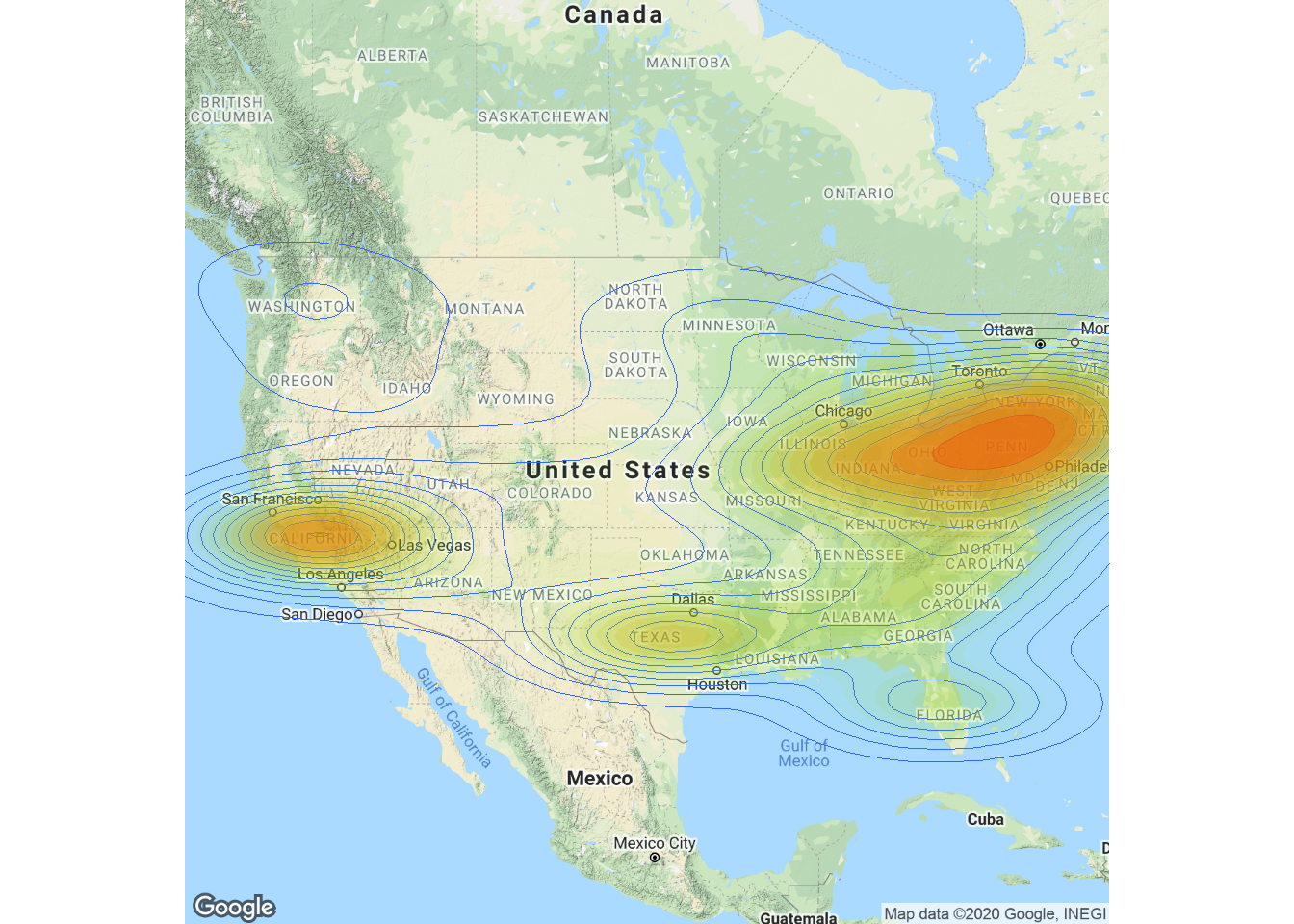
上述範例使用 ggplot2 + ggmap 套件來畫人口密度圖,做圖的第一步是資料載入,包括取得美國各州中心座標資料以及美國各州人口資料
#取得美國各州中心座標資料
StateCenter<-data.frame(
region=tolower(state.name),lon=state.center$x,lat=state.center$y)
head(StateCenter,1)## region lon lat
## 1 alabama -87 33## region value lon lat
## 1 alabama 4777326 -87 33第二個步驟是將人口數字轉換為資料列數,需要這樣轉換的原因是密度圖是用資料列數來決定畫圖的密度,而不是透過單一數值,所以需要在此步驟做轉換
#將人口數值,轉為點!重要!
PopPoint<-NULL
for(i in 1:nrow(StatePop)){
#每100萬人轉為1點
for(j in 1:(StatePop[i,"value"]/1000000)){
PopPoint<-rbind(PopPoint,StatePop[i,])
}
}
head(PopPoint,3)## region value lon lat
## 1 alabama 4777326 -87 33
## 2 alabama 4777326 -87 33
## 3 alabama 4777326 -87 33第三個步驟是作圖
USMap <- get_googlemap(center = c(lon=-99.582,lat=40.091), zoom = 4)
densityMap<-ggmap(USMap, extent = "device") +
geom_density2d(data = PopPoint, aes(x = lon, y = lat), size = 0.3) +
stat_density2d(data = PopPoint,
aes(x = lon, y = lat, fill = ..level.., alpha = ..level..),
size = 0.01, bins = 16, geom = "polygon") +
scale_fill_gradient(low = "green", high = "red", guide = FALSE) +
scale_alpha(range = c(0, 0.3), guide = FALSE)
densityMap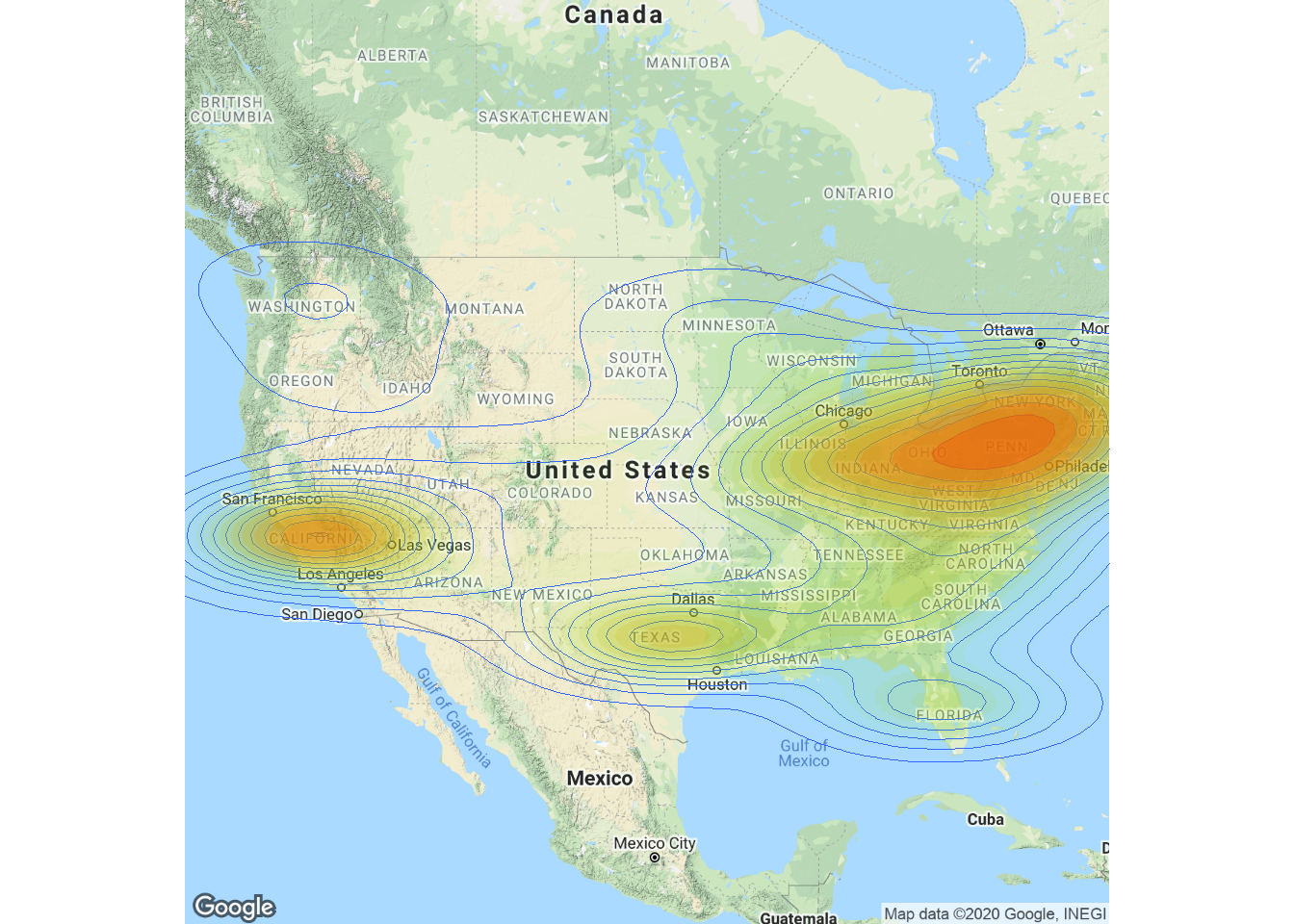
###參考資料 - ggmap package source code - ggmap cheat sheet - ggmap doc
8.4 Taiwan的面量圖
因為畫台灣的面量圖尚無好的套件輔助,但因Open Data的關係,我們可以很容易地取得台灣鄉鎮市邊界的經緯度檔案,通常地圖/邊界經緯度檔案是用空間資料開放格式shapefile .shp儲存,透過政府資料開放平台可以下載台灣的地圖資料,資料集名稱為鄉鎮市區界線。使用shapefile與ggplot2畫圖的步驟如下:
- 取得空間資料檔案
- 使用
rgdal,rgeos,maptoolspackage處理地圖檔shapefile - 使用
ggplot2&RColorBrewer畫圖
上述套件在第一次使用前需要安裝與載入
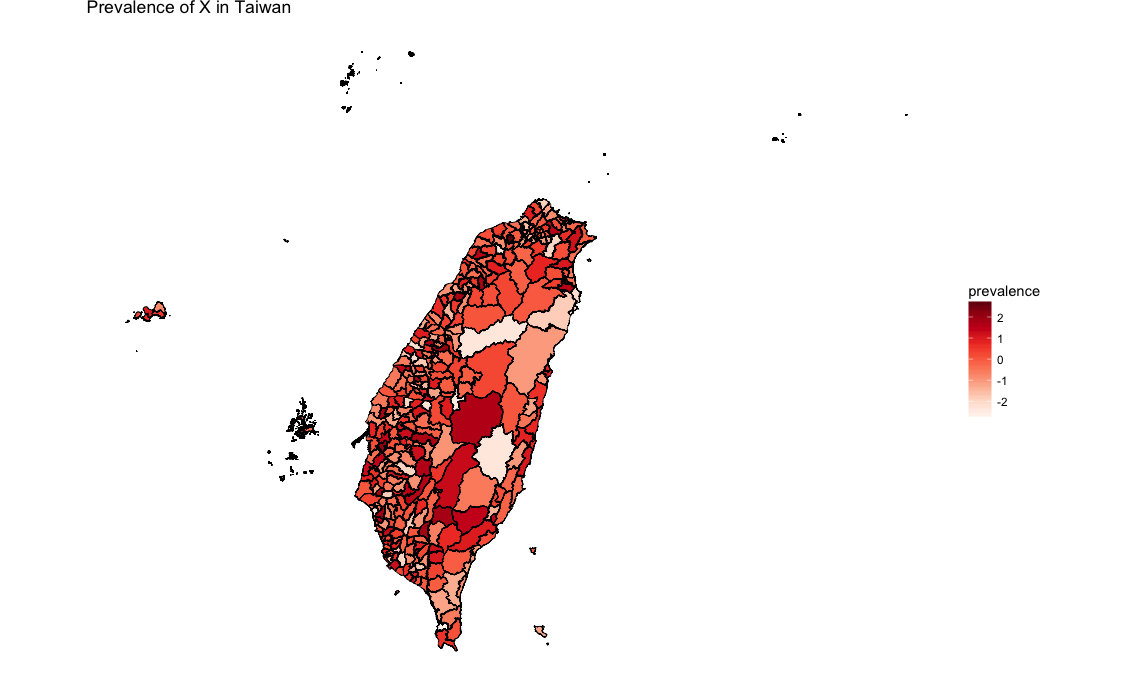
以上各步驟詳述如下: 1. 處理shapefile-1
- 需要
rgdal,rgeos,maptools - fortify: 將
shapefile物件轉為data.frame
library(ggplot2) #for fortify(), ggplot(), ggmap()
head(tw_new$Town_ID)
tw_new.df <- fortify(tw_new, region = "T_UID") #from ggplot2 package
head(tw_new.df,10) long lat order hole piece id group
1 119.9170 26.17518 1 FALSE 1 1 1.1
2 119.9171 26.17517 2 FALSE 1 1 1.1
3 119.9171 26.17518 3 FALSE 1 1 1.1
4 119.9171 26.17518 4 FALSE 1 1 1.1
5 119.9171 26.17518 5 FALSE 1 1 1.1
6 119.9172 26.17518 6 FALSE 1 1 1.1
7 119.9172 26.17518 7 FALSE 1 1 1.1
8 119.9172 26.17518 8 FALSE 1 1 1.1
9 119.9173 26.17515 9 FALSE 1 1 1.1
10 119.9173 26.17515 10 FALSE 1 1 1.1- 做一個假資料來畫:著色基準檔
#做一個假資料來畫
#prevalence設為亂數rnorm(需要的亂數個數)
mydata<-data.frame(NAME_2=tw_new$T_Name, id=tw_new$T_UID,
prevalence=rnorm(length(tw_new$T_UID)))
head(mydata) NAME_2 id prevalence
1 \xa6\xa8\xa5\\\xc2\xed 178 1.0551637
2 \xa8ΥV\xb6m 164 -0.6307466
3 \xb3\xc1\xbcd\xb6m 118 -1.2255327
4 \xba\xf1\xaeq\xb6m 376 0.1314583
5 \xc4\xf5\xc0\xac\xb6m 369 1.3665832
6 \xa5Ф\xa4\xc2\xed 78 -0.3132549- 處理中文編碼 利用iconv將不知所以然的代碼(685\2)轉為看得懂的中文
#from big5 to utf-8
mydata$NAME_2<-iconv(as.character(mydata$NAME_2), #NAME_2原本是factor
from="big5", to = "UTF-8")
head(mydata,10) NAME_2 id prevalence
1 成功鎮 178 1.0551637
2 佳冬鄉 164 -0.6307466
3 麥寮鄉 118 -1.2255327
4 綠島鄉 376 0.1314583
5 蘭嶼鄉 369 1.3665832
6 田中鎮 78 -0.3132549
7 社頭鄉 83 1.2072224
8 竹田鄉 157 0.7312959
9 萬丹鄉 148 1.4849184
10 三灣鄉 64 0.6094254- 合併的圖檔與著色基準檔 最後將有prevalence的假數據mydata和經緯度資料tw_new.df合併, 用merge()
id long lat order hole piece group NAME_2 prevalence
1 1 119.9170 26.17518 1 FALSE 1 1.1 南竿鄉 0.9584632
2 1 119.9171 26.17517 2 FALSE 1 1.1 南竿鄉 0.9584632
3 1 119.9171 26.17518 3 FALSE 1 1.1 南竿鄉 0.9584632
4 1 119.9171 26.17518 4 FALSE 1 1.1 南竿鄉 0.9584632
5 1 119.9171 26.17518 5 FALSE 1 1.1 南竿鄉 0.9584632
6 1 119.9172 26.17518 6 FALSE 1 1.1 南竿鄉 0.9584632
7 1 119.9172 26.17518 7 FALSE 1 1.1 南竿鄉 0.9584632
8 1 119.9172 26.17518 8 FALSE 1 1.1 南竿鄉 0.9584632
9 1 119.9173 26.17515 9 FALSE 1 1.1 南竿鄉 0.9584632
10 1 119.9173 26.17515 10 FALSE 1 1.1 南竿鄉 0.9584632- 畫台灣面量圖
library(RColorBrewer) #配色用brewer.pal( 9 , "Reds" )
twcmap<-ggplot() +
geom_polygon(data = final.plot,
aes(x = long, y = lat, group = group,
fill = prevalence),
color = "black", size = 0.25) +
coord_map()+#維持地圖比例
scale_fill_gradientn(colours = brewer.pal(9,"Reds"))+
theme_void()+
labs(title="Prevalence of X in Taiwan")
twcmap
8.4.1 ggmap+面量圖
library(ggmap)
twmap <- get_googlemap(center = c(lon=120.58,lat=23.58),
zoom = 7,language = "zh-TW")
ggmap(twmap)+ #ggmap
geom_polygon(data = final.plot, #面量圖
aes(x = long, y = lat, group = group, fill = prevalence),
color = "grey80", size = 0.1,alpha = 0.5) +
scale_fill_gradientn(colours = brewer.pal(9,"Reds"))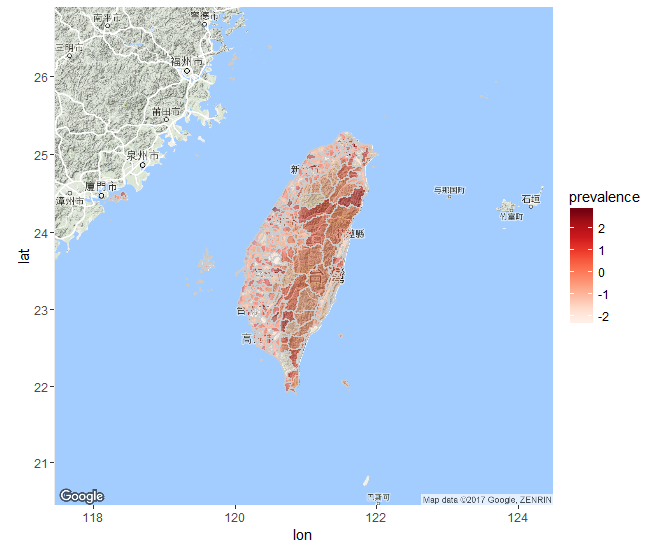
##Heatmap
Heatmap熱度圖使用顏色的深淺來表示數值的大小,通常會搭配XY兩軸的變量,所以使用一張圖就能表示三個維度的資訊,在ggplot2套件中,可以使用geom_tile()來畫Heatmap,以下以NBA球員的資料作為範例,希望能透過Heatmap來呈現球員表現的差異。
首先先將檔案讀入
## Name G MIN PTS FGM FGA FGP FTM FTA FTP X3PM X3PA X3PP ORB DRB
## 1 Dwyane Wade 79 39 30 10.8 22 0.49 7.5 9.8 0.76 1.1 3.5 0.32 1.1 3.9
## 2 LeBron James 81 38 28 9.7 20 0.49 7.3 9.4 0.78 1.6 4.7 0.34 1.3 6.3
## 3 Kobe Bryant 82 36 27 9.8 21 0.47 5.9 6.9 0.86 1.4 4.1 0.35 1.1 4.1
## 4 Dirk Nowitzki 81 38 26 9.6 20 0.48 6.0 6.7 0.89 0.8 2.1 0.36 1.1 7.3
## 5 Danny Granger 67 36 26 8.5 19 0.45 6.0 6.9 0.88 2.7 6.7 0.40 0.7 4.4
## 6 Kevin Durant 74 39 25 8.9 19 0.48 6.1 7.1 0.86 1.3 3.1 0.42 1.0 5.5
## TRB AST STL BLK TO PF
## 1 5.0 7.5 2.2 1.3 3.4 2.3
## 2 7.6 7.2 1.7 1.1 3.0 1.7
## 3 5.2 4.9 1.5 0.5 2.6 2.3
## 4 8.4 2.4 0.8 0.8 1.9 2.2
## 5 5.1 2.7 1.0 1.4 2.5 3.1
## 6 6.5 2.8 1.3 0.7 3.0 1.8為了做圖,將寬表轉長表,寬表與長表的概念可參見6.8
## Name variable value
## 1 Dwyane Wade G 79
## 2 LeBron James G 81
## 3 Kobe Bryant G 82
## 4 Dirk Nowitzki G 81
## 5 Danny Granger G 67
## 6 Kevin Durant G 74
## 7 Kevin Martin G 51
## 8 Al Jefferson G 50
## 9 Chris Paul G 78
## 10 Carmelo Anthony G 66將Geometric objects指定為geom_tile(),完成Heatmap
library(ggplot2) #for ggplot()
ggplot(nba.m, aes(variable, Name)) + #aes(x,y)
geom_tile(aes(fill = value),colour = "white")+ #geom_tile: 區塊著色
scale_fill_gradient(low = "white",high = "steelblue") #數值低:白色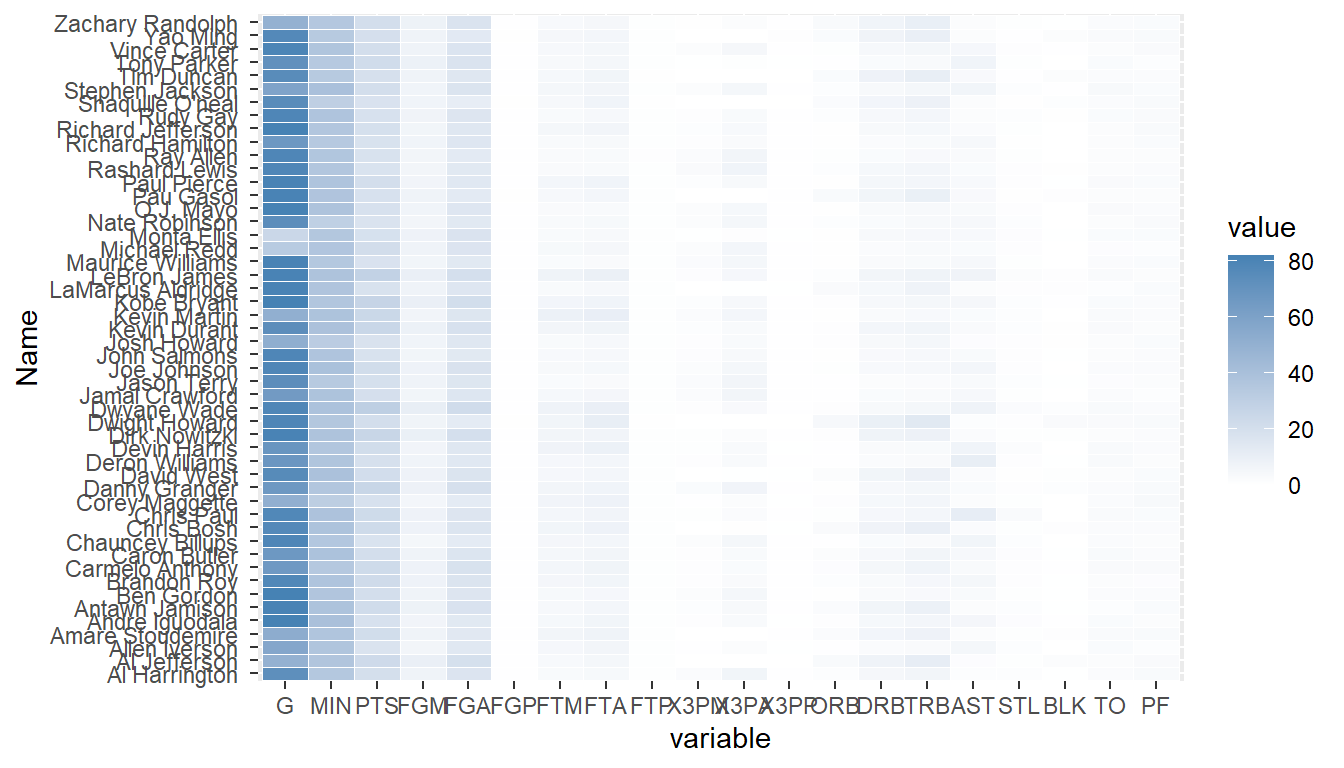
看上圖可以發現,因為G欄資料明顯大於其他欄位,導致顏色差異不明顯,為了解決此問題,將個欄位的資料標準化處理,這邊使用到apply函式
apply()有類似for迴圈的功能
- apply(Data, MARGIN, FUN,…)
- Data:矩陣(Matrix),Data Frame
- MARGIN:1=row, 2=column
- FUN:函數
- …:函數要用的參數
## Name G MIN PTS FGM FGA FGP FTM FTA FTP X3PM X3PA X3PP
## 1 Dwyane Wade 0.62 1.00 3.2 2.9 2.6 0.51 1.9 2.1 -0.74 -0.11 0.13 -0.157
## 2 LeBron James 0.77 0.61 2.6 2.0 1.7 0.46 1.8 1.9 -0.52 0.49 0.70 0.027
## ORB DRB TRB AST STL BLK TO PF
## 1 -0.272 -0.35 -0.33 1.7 2.6 1.21 1.8 -0.3
## 2 -0.061 1.01 0.66 1.5 1.4 0.86 1.1 -1.4nba.m <- melt(nba) ##寬轉長
ggplot(nba.m, aes(variable, Name)) +
geom_tile(aes(fill = value),colour = "white")+ #geom_tile: 區塊著色
scale_fill_gradient(low = "white",high = "steelblue") #數值低:白色
8.5 Treemap
Treemap(矩形式樹狀結構繪圖法)是以二維平面的方式展示包含階層結構(hierarchical)形式的統計資訊,在R中可以使用treemapify(Wilkins 2019) packages
install.packages("devtools")
library(devtools)
install_github("wilkox/ggfittext")
install_github("wilkox/treemapify") 以G20 Dataset為例,二十國集團(英語:Group of Twenty,縮寫:G20)是一個國際經濟合作論壇,於1999年12月16日在德國柏林成立,屬於布雷頓森林體系框架內非正式對話的一種機制,由七國集團(美國、英國、法國、德國、義大利、日本、加拿大),金磚五國(中國、印度、巴西、俄羅斯、南非),七個重要經濟體(澳大利亞、墨西哥、韓國、土耳其、印尼、沙烏地阿拉伯、阿根廷),以及歐盟組成。按照慣例,國際貨幣基金組織與世界銀行列席該組織的會議。二十國集團的GDP總量約佔全球GDP的85%,貿易佔全球貿易總額的80%以上,人口約佔全球人口的2/3。(維基百科)
G20 Dataset包含20個國家的資訊,資料欄位有:
- Region 國家所在區域
- Country 國家名稱
- Trade.mil.USD 總貿易額,以百萬為單位
- Nom.GDP.mil.USD 名義國內生產總值,以百萬為單位
- HDI 人類發展指數(維基百科)
- Population 人口數
- Economic.classification 經濟狀況分類
首先將資料讀入,並用str()函式觀察資料型態
## 'data.frame': 20 obs. of 6 variables:
## $ region : Factor w/ 8 levels "Africa","Asia",..: 1 6 6 6 8 8 2 2 2 2 ...
## $ country : Factor w/ 20 levels "Argentina","Australia",..: 16 20 4 13 3 1 5 12 17 9 ...
## $ gdp_mil_usd : int 384315 15684750 1819081 1177116 2395968 474954 8227037 5963969 1155872 1824832 ...
## $ hdi : num 0.629 0.937 0.911 0.775 0.73 0.811 0.699 0.912 0.909 0.554 ...
## $ econ_classification: Factor w/ 2 levels "Advanced","Developing": 2 1 1 2 2 2 2 1 1 2 ...
## $ hemisphere : Factor w/ 2 levels "Northern","Southern": 2 1 1 1 2 2 1 1 1 1 ...用搭配ggplot()函數,使用geom_treemap()做圖
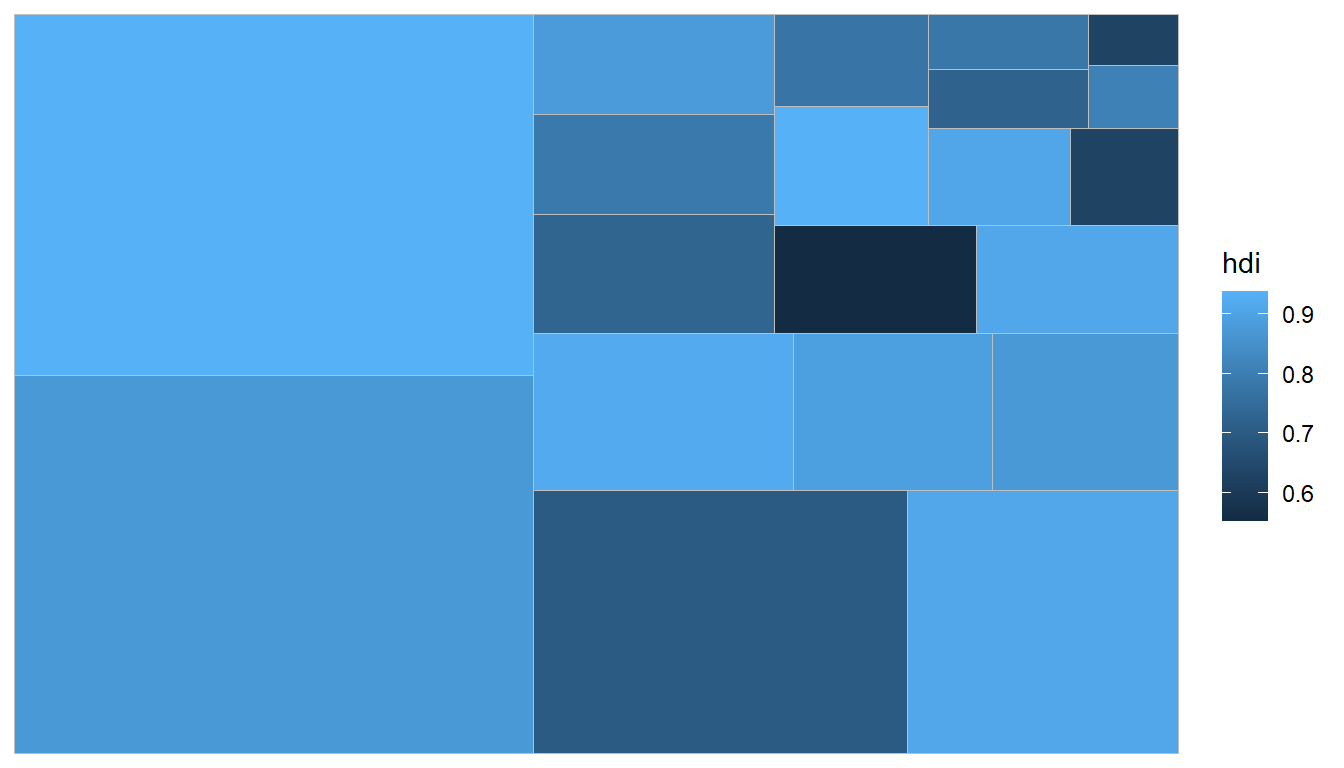
看函式名稱不難了解ggplotify()也是基於ggplot2套件開發,所以可以使用ggplot2的圖形設定參數改變圖形樣式,由於數字越大顏色越深比較符合視覺化的常理,所以這邊使用ggplot2的scale_fill_gradient()函式指定數值高低所需的顏色
ggplot(G20, aes(area = gdp_mil_usd, fill = hdi, label = country)) +
geom_treemap() +
scale_fill_gradient(low = "white",high = "steelblue") #指定高低顏色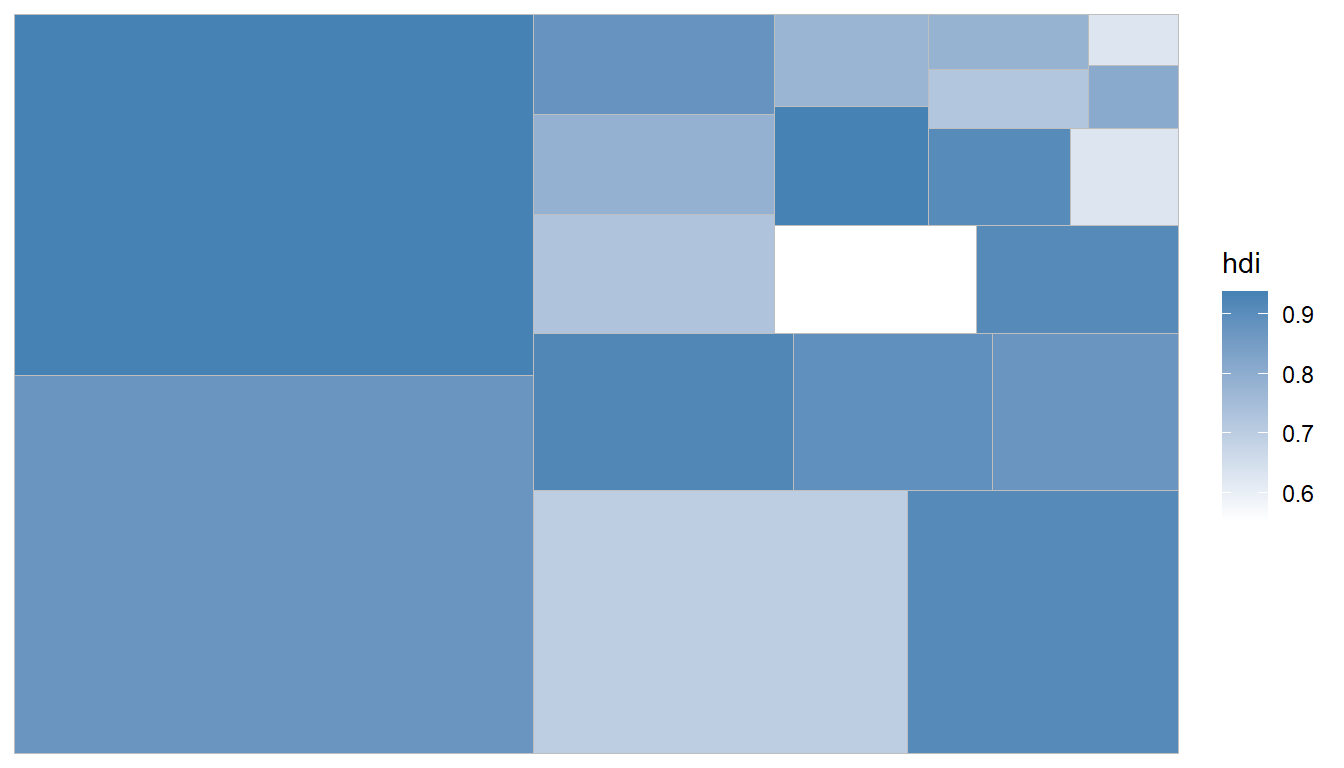
也可使用geom_treemap_text()加上文字標籤。
ggplot(G20, aes(area = gdp_mil_usd, fill = hdi, label = country)) +
geom_treemap() +
scale_fill_gradient(low = "white",high = "steelblue") #指定高低顏色+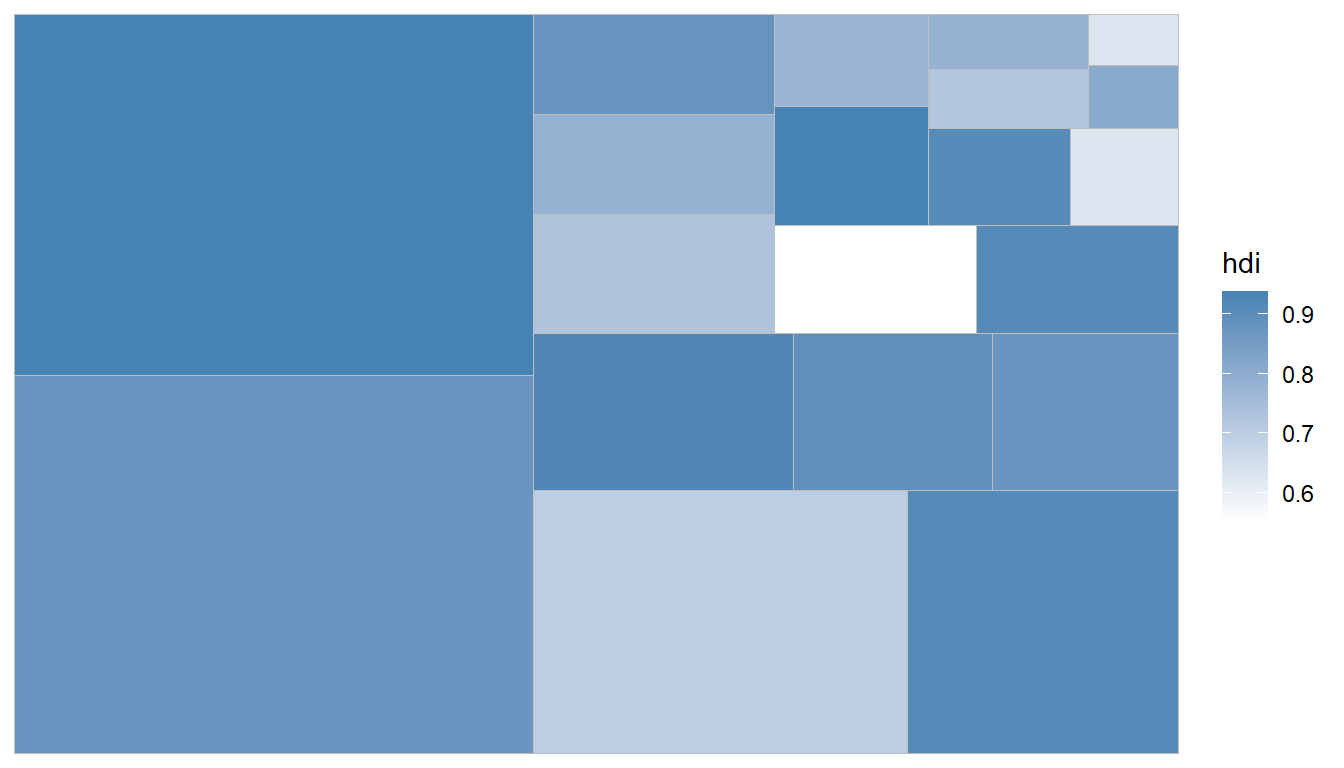
## geom_treemap_text: na.rm = FALSE, padding.x = 1, padding.y = 1, place = centre, min.size = 4, grow = TRUE, reflow = FALSE, fixed = NULL, layout = squarified, start = bottomleft
## stat_identity: na.rm = FALSE
## position_identity完整做圖程式碼如下:
## install.packages("devtools") 第一次使用前需要安裝
## library(devtools)
## install_github("wilkox/treemapify")
library(treemapify)
data(G20)#載入範例資料
ggplot(G20, aes(area = gdp_mil_usd, fill = hdi, label = country)) +
geom_treemap() +
scale_fill_gradient(low = "white",high = "steelblue") #指定高低顏色+
geom_treemap_text(fontface = "italic", colour = "white", place = "centre",
grow = TRUE)treemap(Tennekes 2017) package也提供相同的功能
library(treemap)
data(GNI2014)
treemap(GNI2014,
index=c("continent", "iso3"), #分組依據
vSize="population", #區塊大小
vColor="GNI", #顏色深淺
type="value")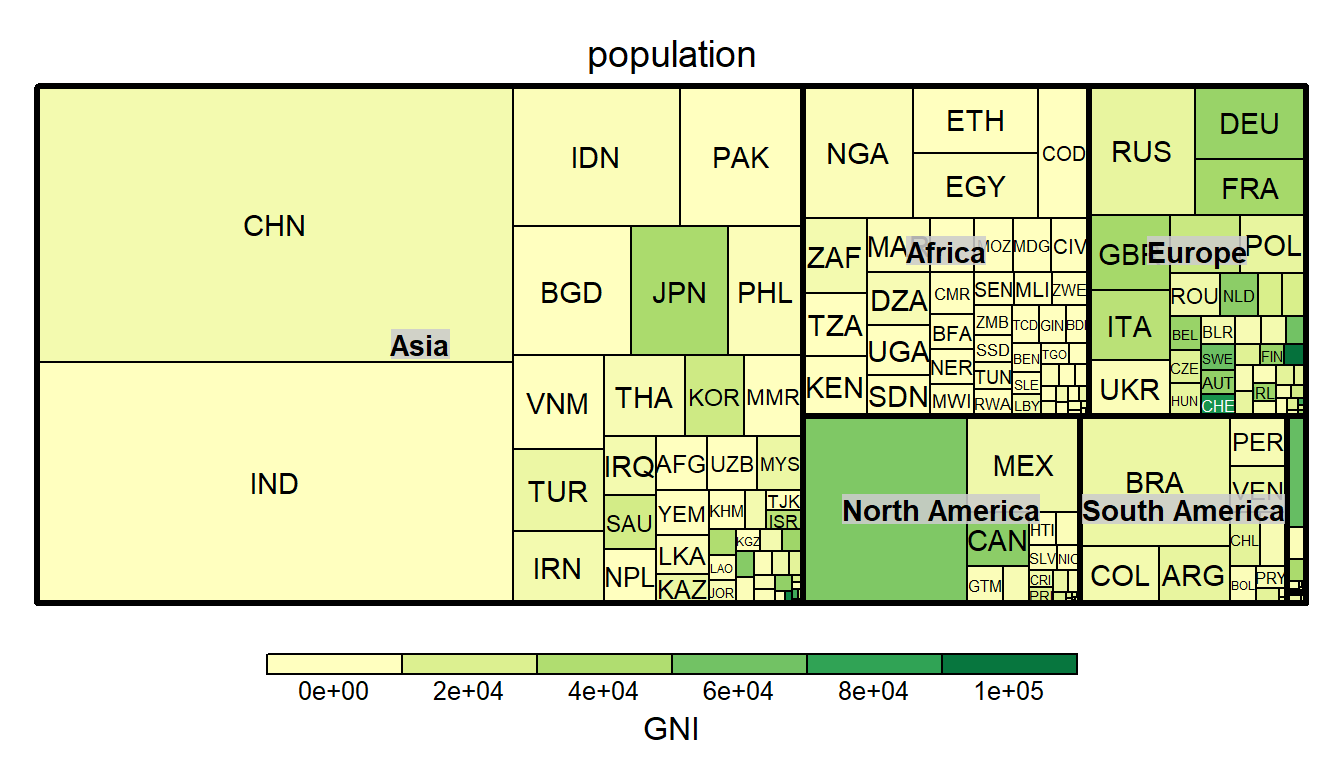
8.6 參考文件與資源
- 官方網站文件
- RStudio製作的ggplot cheat sheet
- DataCamp互動式課程1 Data Visualization with ggplot2 (Part 1)
- DataCamp互動式課程2 Data Visualization with ggplot2 (Part 2)
- DataCamp互動式課程3 Data Visualization with ggplot2 (Part 3)
References
Arel-Bundock, Vincent. 2020. WDI: World Development Indicators and Other World Bank Data. https://CRAN.R-project.org/package=WDI.
Kahle, David, Hadley Wickham, and Scott Jackson. 2020. Ggmap: Spatial Visualization with Ggplot2. https://github.com/dkahle/ggmap.
Lamstein, Ari. 2018. Choroplethr: Simplify the Creation of Choropleth Maps in R. https://CRAN.R-project.org/package=choroplethr.
Tennekes, Martijn. 2017. Treemap: Treemap Visualization. https://CRAN.R-project.org/package=treemap.
Wickham, Hadley, Winston Chang, Lionel Henry, Thomas Lin Pedersen, Kohske Takahashi, Claus Wilke, Kara Woo, Hiroaki Yutani, and Dewey Dunnington. 2020. Ggplot2: Create Elegant Data Visualisations Using the Grammar of Graphics. https://CRAN.R-project.org/package=ggplot2.
Wilkins, David. 2019. Treemapify: Draw Treemaps in ’Ggplot2’. https://CRAN.R-project.org/package=treemapify.